O que é Big Data
Quantidade e variedade de dados. 80% dos dados são não-estruturados(dados não padrões), ou estão em diferentes formatos. Dificuldade de coleta e tratamento de dados. Modelos atuais de BD visam armazenamento estruturado(padrão). Logs de servidores não são utilizados como deveriam, pois poderiam prever um futuro através da análise, contornando problemas e otimizando soluções. Logs de servidores são exemplos de Big Data. Custo alto em manter dados não-estruturados. Os dados de hoje são o novo petróleo como matéria-prima para os negócios, ainda mais com o crescimento em IOT. Big Data é conjunto de dados, grande, complexo e valioso, que não podem ser processados por BD ou aplicações tradicionais. Esses valores, em pequenas quantidades, não alcançariam resultados concretos. Os dados podem ser estruturados, não-estruturados ou streaming(fluxo constante de dados). O Big Data tornou-se importante pela existência de ferramentas que fazem esta análise com baixo custo. Machine Learning e IA são dependentes de Big Data.Nele, os dados precisam ser confiáveis!
Tamanho do Big Data
Yottabyte -> x1024 -> Zettabyte -> x1024 -> Exabyte -> x1024 -> Petabyte -> 1024 -> Terabyte -> x1024 -> Gigabyte.
A ideia é que, com o tempo, o nº de armazenamento cresça de forma gradual.
Exemplo atual
A Netflix analisa seus dados de filmes/séries assistidas, favoritos, para então recomendar conteúdo similar ao seu e outros perfis similares. A coleta de dados, transformação em informação, recomendações e análise preditiva são pontos levados em consideração nesse caso.
Tecnologias atuais
- Linguagens de programação como R, Python
- Frameworks como Hadoop, Spark, Azure Machine Learning
Os 4 V's do Big Data
- Volume(25%): Tamanho dos dados;
- Variedade(69%): Formato dos dados;
- Velocidade(6%): Geração dos dados;
- Veracidade: Confiabilidade dos dados.
À quem insira o 5º V, de 'valor', mas que não fora contabilizado aqui, pois conclui-se que o valor é o resultado da análise de Big Data, não de suas características.
Aplicações práticas
- Transformar TB de Tweets gerados cada dia em produtos de análise de sentimento;
- Investigar milhões de eventos de trade nas bolsas de valores a fim de identificar fraudes;
- Monitorar milhares de vídeos de segurança a fim de identificar pontos perigosos em uma cidade.
Uso do Big Data
Sistema de recomendações, análises em tempo real, construir um modelo de série de análises temporais, prever o preço de um produto de sua empresa daqui a um mês/ano, prever o resultado de uma campanha de marketing, prever o turnover(se o funcionário vai sair ou não da empresa).
Apache Hadoop

Framework livre, com função de armazenamento e processamento compartilhado e distribuído em larga escala de conjunto de dados, com foco em criação de clusters de baixo custo. Em síntese, é um conjunto de softwares que gerencia um cluster(várias máquinas atuando na mesma função) para leitura e escrita de grande conjunto de dados, com baixo custo. O Hadoop permite que os computadores(nodes) executam aplicações em sistemas distribuídos envolvendo Petabytes de dados. Logo Hadoop surgiu por razão do nome do elefante de pelúcia da filha de um dos desenvolvedores. Hadoop não é um BD. Seu objetivo é gerenciar dados e armazená-los em forma de arquivo, através do HDFS. O Hadoop compõe-se de 3 módulos:
- Hadoop Distributed File System(HDFS): Gerenciamento de arquivos(armazenamento) de várias máquinas como um individual, como um grande HD;
- Hadoop Yarn: Gestor dos processos de leitura e escrita no HDFS;
- Hadoop MapReduce: Processar dados em ambiente distribuído. O HDFS gerencia o armazenamento e o MapReduce o processamento. O Apache Spark surgiu com a tentativa de substituir o MapReduce, rodando sob o HDFS, sendo mais eficiente que o MapReduce.
Características:
- Baixo custo, sendo gratuito e livre;
- Escalável, permitindo aumentar a infraestrutura;
- Tolerante a falhas, com correção de problemas automaticamente e recuperação de falhas rápida;
- Flexível, para montar arquiteturas de acordo com a necessidade.
HDFS
- Tolerante a falhas e recuperação automática (falha 1 máquina do cluster, as outras continuam normalmente);
- Portabilidade entre hardware e SOs heterogêneos;
- Escalabilidade para armazenamento e processamento de grandes conjuntos de dados;
- Confiabilidade, através da manutenção de várias cópias de dados.
MapReduce
- Flexibilidade, processando todos os dados de forma independente do tipo e formato(estruturado ou não-estruturado);
- Confiabilidade, permitindo que os jobs(pacote de execução para o cluster Hadoop) sejam executados em paralelo, em caso na falha de um os outros não serão afetados;
- Acessibilidade, suportando várias linguagens de programação, como Python, Java, C++, etc.
Apache HDFS
Foi desenvolvido de forma WORM(Write Once, Read Many Times). O cluster possui 2 tipos de nodes:
- Namenode(Master, gestora do cluster)
- Gerencia a estrutura do filesystem;
- Gerencia os metadados de todos os arquivos e diretórios de toda a estrutura;
- Datanode(Worker)
- Armazena e busca bloco de dados solicitados pelo Namenode ou cliente;
- Reporta periodicamente para o Namenode com a lista de blocos que foram armazenados.
Apache MapReduce
Modelo de programação para processamento e geração de grandes conjuntos de dados. Transforma o problema de análise em um processo computacional, com conjunto de chaves e valores. Foi desenvolvido para tarefas que consomem tempo em computadores conectados em rede, de alta velocidade, gerenciados por um único master. O MapReduce usa um tipo de análise de dados por força bruta, onde todo conjunto de dados é processado em cada query. Usa modelo de processamento em batch.
Funcionamento:
A função de mapeamento converte os valores em pares de chaves(K)/valor(V). A regra de mapeamento é definida pelo cientista de dados, que resultará em grupos contendo Chaves e Valores.
Dados -> Mapeamento -> K1:V, K2:V, K3:V, K4:V
Ex: Sistema de recomendação de filmes. Os dados foram coletados, cria-se a regra de mapeamento, onde o ID do usuário que avaliou(K) com sua respectiva nota(V).
Big Data -> Mapeamento -> Redução(ões) -> Resultado
MapReduce permite a execução de queries ad-hoc(executada direto no cluster, via terminal) em todo conjunto de dados em tempo escalável. MapReduce combina dados de múltiplas fontes de forma efetiva. O segredo está no balanceamento entre seeking e transfer: reduzir operações de seeking, e usar de forma efetiva as operações de transfer. MapReduce é bom para atualizar uma grande parte do conjunto de dados, ao contrário dos BDs Relacionais, que são melhores para atualizar algo específico. Os BDs Relacionais usam o B-Tree, dependente de operações de seek. O MapReduce usa operações de SORT e Merge, para recriar o BD, sendo mais eficiente. O MapReduce foca no Transfer, enquanto os BDs Relacionais usam Seeking. Dessa forma, é muito efetivo no processamento de dados semi ou não estruturados, pois interpreta dados durante sessões de processamento de dados. Ele não utiliza propriedades intrínsecas. Os parâmetros usados para selecionar os dados são definidos pelo profissional. Primeiro armazena, depois interpreta. Nos BDs geralmente primeiro cria-se o planejamento, depois o armazenamento.
- Seek Time: Delay para encontrar um arquivo;
- Transfer Rate: Velocidade para encontrar um arquivo (melhor que seek time).
Tipos de dados
- Dados Estruturados: Dados representados de forma tabular (MySQL);
- Dados Semi Estruturados: Dados que não possuem um modelo de forma de organização (XML);
- Dados Não Estruturados: Dados sem estrutura pré-definida (Big Data, ex: Comentários do Youtube com logs de um servidor, como colocar isso dentro de um BD Relacional? não funcionará).
Arquitetura Hadoop
Hadoop
- Conceito de job;
- Cada job é uma unidade de trabalho;
- Não há controle de concorrência;
- Qualquer tipo de dado pode ser usado;
- Dados em qualquer formato;
- Modelo apenas de leitura;
- Máquinas de custo baixo podem ser usadas;
- Simples, mas eficiente mecanismo de tolerância a falha.
BD Relacional(RDBMS)
- Conceito de transações;
- Uma transação é uma unidade de trabalho;
- Controle de concorrência;
- Dados estruturados com controle de esquema;
- Modelo de leitura/escrita;
- Servidores de maior custo são necessários;
- Falhas são raras de ocorrer;
- Mecanismos de recuperação.
Cluster
Várias máquinas comportando-se como apenas uma. Um Rack(estrutura) possui vários nodes(máquinas) plugadas na rede, com um software para gerenciá-las como apenas uma(Apache Hadoop), a fim de processamento(MapReduce ou Apache Spark) e armazenamento(HDFS).
Arquitetura Cluster Hadoop
Possui 2 tipos de nodes: Master(Namenode, gestor) e Slaves(Worker).
MasterNode
- Storage (HDFS, Namenode);
- Processamento (MapReduce, JobTracker).
SlaveNode
- Storage (HDFS, DataNode)
- Processamento (MapReduce, TaskTracker).
Serviços
MapReduce: JobTracker³(Master) -> TaskTracker⁴(Slaves)
HDFS: NameNode¹ -> DataNode²(Slaves)
- Gerenciar o armazenamento distribuído. Secondary NameNode: Trabalha em conjunto com o NameNode;
- Armazenam os dados, de forma distribuída, em forma de blocos. Gera-se um bloco réplica, em outro DataNode, para o caso de falha;
- Gestor responsável por disparar o job de processamento MapReduce, que serão executados sob os dados armazenados no HDFS;
- Executa as tarefas(jobs), no Slave, disparadas pelo Master.
Máquinas e funções
- MasterNode: JobTracker(Processamento com MapReduce) e NameNode(Armazenamento com HDFS) com Secondary NameNode;
- SlaveNodes: DataNode e TaskTracker(Armazenamento e processamento).
Funcionamento(Hadoop e Spark)
Passo 1
Pc cliente -> Dados -> MasterNode(Storage com HDFS e NameNode / Armazenamento com MapReduce e JobTracker) -> SlaveNodes(Storage com HDFS e DataNode / Processamento com MapReduce e TaskTracker) * Pc do cliente envia os dados/arquivos/etc ao Master através de uma carga ETL com o software Scope, advindos de um BD ou qualquer outro meio.
Passo 2
Enviar algoritmo de mapeamento e redução (Python, R, Scala...), que será interpretado pelo MapReduce. Pc cientista -> Algoritmo -> Armazenará o job no MasterNode(Storage com HDFS e NameNode / Processamento com MapReduce e JobTracker) -> SlaveNode(Armazenamento dos blocos de dados com HDFS e DataNode / Processamento com MapReduce e TaskTracker) * O processo será o acionamento do NameNode através do JobTracker(consulta) e TaskTracker, executa o processamento e retorna os dados para o cliente/aplicação.
Configuração Hadoop
- Modo Standalone: Todos os serviços Hadoop executados em única JVM, no mesmo servidor(Master e Slave na mesma máquina). Ideal para ambiente de teste;
- Pseudo Distribuído: Serviços individuais Hadoop atribuídos a JVM's individuais, no mesmo servidor(Única máquina, com JVM's separadas). Ideal para ambiente de teste simulando cluster, utiliza mais memória;
- Totalmente Distribuído: Serviços individuais do Hadoop executados em JVM's individuais, através do cluster. Ideal para ambiente de produção.
Arquitetura HDFS
- Os serviços NameNode e SecondaryNode constituem os serviços Master. Os DataNode são os Slaves. Pode-se ter uma máquina NameNode e outra SecondaryNode, ambas representando o Master;
- O Master é responsável por aceitar jobs do cliente e garantir que os dados requeridos para a operação sejam carregados e segregados em blocos de dados. Eles serão carregados e segregados de acordo com os arquivos de configuração personalizados pelo cientista(quantos blocos deseja, tamanho de cada bloco...);
- O HDFS permite que os dados sejam armazenados em arquivos, cada um dividido em um ou mais blocos, que são armazenados e replicados pelos DataNodes. Os blocos são distribuídos para o sistema de DataNodes dentro do cluster, garantindo que as réplicas sejam mantidas(tolerância a falhas);
- As réplicas de cada bloco são distribuídas em máquinas em todo o cluster para permitir acesso de dados confiável e rápido.
Arquitetura MapReduce
Input(grande volume) -> Mapeamento(classificação) -> Redução(classificados) -> Output(Volume abstraído)
Para o funcionamento, deve-se aplicar o MapReduce, dividir e subdividir o conjunto de dados em listas ordenadas. O MapReduce foi projetado para usar computação paralela distribuída em Big Data e transformar os dados em pedaços menores. No Mapeamento(Map), os dados são separados em pares(Key-Value), transformados e filtrados. Então os dados são distribuídos para os nodes e processados. Na Redução(Reduce), os dados são agregados em conjuntos de dados(datasets) menores, transformados então em um formato padrão de Key-Value, onde Key funciona como identificador e o Value é o conteúdo. Todo o processo inicia-se com a requisição feita pelo cliente e job(comando(s)) submetido(executado). O JobTracker encarrega-se de coordenar como o job será distribuído. No mapeamento, os dados de entrada são, primeiramente, distribuídos em Key-Value e divididos em fragmentos, que são atribuídos a tarefas de mapeamento. Na Redução dos Dados, cada operação de redução dos dados tem fragmento atribuído, e então o processo é executado e o resultado final é gerado.
Cache distribuído e Segurança
Distributed Cache é uma funcionalidade do Hadoop que permite cache dos arquivos usados pelas aplicações. Isso permite performance quando tarefas de Map e Reduce precisam acessar dados em comum. Permite também que um node do cluster acesse os arquivos no filesystem local, ao invés de solicitar o arquivo em outro node. É possível de fazer cache de zip e tar.gz. O Hadoop utiliza o Kerberos, mecanismo de autenticação usado, por exemplo, no sistema de diretórios dos servidores Windows e Linux. Por padrão, o Hadoop é executado no modo não-seguro, em que não é necessário autenticação. Após configurado, o Hadoop é executado em modo de segurança e cada usuário e serviço precisa ser autenticado pelo Kerberos. Apó Kerberos configurado, a autenticação Kerberos é usada para validar as credenciais do lado cliente, devendo solicitar uma aplicação de serviço válido para o Hadoop.
Ecossistema Hadoop
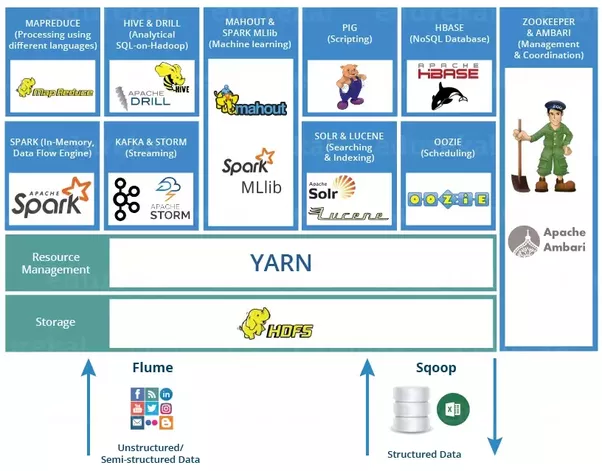
São o conjunto de ferramentas que compõem as funcionalidades que rodam sob o HDFS. Muito similar os Apps rodando sob um SO. Os Apps servem para aprimorar a capacidade do SO.
Apache Zookeeper (Guardião do Zoo)
Solução de alta performance para coordenação de serviços em aplicações distribuídas. É um serviço de coordenação distribuída para gerenciar grandes conjuntos de hosts(clusters). Isso permite que os desenvolvedores se preocupem apenas com a lógica do aplicativo, ignorando sua natureza distribuída. Por exemplo, o HBbase(BD NoSQL) usa o Zookeeper para acompanhar o estado de dados distribuídos através do cluster. O Zookeeper proporciona um ponto comum de acesso a uma ampla variedade de objetos utilizados em ambientes de cluster.
Apache Oozie (Workflow)
Gerenciador de fluxo de trabalho(workflow), permitindo agendamento automatizado dos jobs de MapReduce e gerencie-os através do cluster. O Oozie é integrado com o restante dos componentes do Hadoop para apoiar vários tipos de trabalhos do Hadoop(Java Map-Reduce, streaming Map-Reduce, Pig, Hive e Sqoop), bem como jobs do sistema(algoritmos Java e shell). Ele permite ao usuário definir uma série de jobs diferentes(MapReduce, Pig, Hive) e ligá-los um ao outro. Por exemplo, que determinada consulta somente é iniciada após os jobs que acessem os mesmos dados sejam concluídos.
Apache Hive ('Plugin' de Data Warehouse)
Data Warehouse(sistema de gerenciamento de dados projetado para ativar e fornecer suporte às atividade de BI) que funciona com Hadoop e MapReduce. É um sistema de armazenamento de dados para Hadoop, que facilita a agregação dos dados para análises e relatórios com Big Data. Permite queries usando uma linguagem SQL-Like, denominada HiveQL(HQL). Provê a capacidade de tolerância a falha para armazenamento de dados e depende do MapReduce para execução. Permite conexões JDBC/ODBC, facilmente integrado com outras ferramentas de BI como Tableau, Microstrategy, Microsoft Power BI, etc. O Hive é orientado a Batch. Assim como o Pig, gera jobs MapReduce que executam no cluster Hadoop. É um sistema para gestão de query de dados não estruturados, em formato estruturado. O Hive utiliza MapReduce para execução e HDFS para armazenamento e pesquisa de dados. Exemplo de query HQL: "SELECT * FROM tabela;".
Apache Sqoop (SQL-to-Hadoop)
Projeto com função de importar/exportar dados de BD's Relacionais, permitindo mover dados como Microsoft SQL Server ou Oracle para o Hadoop. O desenvolvedor pode escolher para importar, banco inteiro, determinadas tabelas e até determinadas colunas ou linhas. O Sqoop também gera classes Java de fácil interação com os dados importados, usando conexão JDBC para conectar com BD's Relacionais. Pode também criar tabelas no Hive e suporta importação incremental. Exemplo de código para importar dados de MySQL para o HDFS Hadoop: "sqoop list-tables-username nome -password senha \ --connect jdbc:mysql//dbname".
Apache Pig (Análise)
Ferramentas usada para analisar grandes conjuntos de dados, que representam fluxos de dados. Todas as manipulações de dados no Hadoop podem ser feitas com o Pig. Para escrever programas de análise de dados, Pig oferece uma linguagem chamada Pig Latin, que fornece vários operadores para uso nas próprias funções de leitura, escrita e processamento de dados. Para essa análise, com o Pig, devem ser criados scripts com Pig Latin, que serão convertidos, internamente, para jobs MapReduce, com o componente denominado Pig Engine.
- Pig Latin Script Engine
- Linguagem procedural de fluxo de dados;
- Sintaxe e comandos que podem ser aplicados para implementar lógica dos negócios.
- Runtime Engine
- Compilador que produz sequências de programas MapReduce;
- Usa HDFS para armazenar e buscar dados;
- Usado para interagir com sistemas Hadoop;
- Valida e compila scripts em sequência de jobs MapReduce.
Pig
- Linguagem de script usada para interagir com HDFS;
- Passo a passo;
- Avaliação não imediata;
- Permite resultados intermediários.
SQL
- Linguagem de query usada para interagir com BD;
- Bloco único;
- Avaliação imediata;
- Requer join executado 2 vezes ou materializado como um resultado intermediário.
Apache HBase (BD)
BD NoSQL para Big Data, que roda sob HDFS, para armazenar bilhões de registros. Possui modelo de dados semelhante ao BigTable do Google. Aproveita a tolerância a falhas do HDFS. O HBase é uma parte do ecossistema Hadoop que fornece acesso aleatório de leitura/gravação aos dados do HDFS em tempo real. É um tipo de BD NoSQL com modelo Key-Value, ambas do tipo byte-array. Na arquitetura, possui 2 tipos de Nodes: Master e RegionServer.
- Master
- Só 1 node Master pode ser executado. A alta disponibilidade é mantida pelo Zookeeper;
- Responsável pela gestão de operações de cluster, como assignment, load balancing e splitting;
- Não faz parte de operações de read/write.
- RegionServer
- Podem ser vários;
- Responsável por analisar as tables, realizar leituras e buffers de escrita;
- O cliente comunica com ele para processar operações de read/write.
Comparação entre HBase e RDBMS:
- HBase
- Particionamento automático;
- Escalado de forma linear e automática com novos nodes;
- Usa hardware commodity;
- Tolerante a falhas.
- RDBMS
- Particionamento automático ou manual, realizado pelo admin;
- Escalado verticalmente com a adição de mais hardware;
- Requer hardware mais robusto;
- Tolerante ou não a falhas.
Apache Flume (Imports)
Função de importar dados de diferentes fontes, em tempo real, para o HDFS Hadoop. Possui arquitetura baseada em streaming(fluxo constante) de dados. Deve-se instalar um agente no serviço cliente, para realizar a coleta de dados, que os armazenará diretamente no HDFS ou no HBase. O modelo de dados do Flume permite seu uso em aplicações analíticas online, mas também pode ser usado em Infraestrutura de TI.
Apache Mahout (Machine Learning)
Biblioteca de algoritmos de Machine Learning, escalável e com foco em clustering, classificação de sistemas de recomendação. Permite a utilização dos principais algoritmos de clustering, testes de regressão e modelagem estatística e os implementa usando modelo MapReduce. Machine Learning permite modelagem preditiva(prever futuro com base no histórico).
Apache Kafka (Análise RealTime)
Sistema para gerenciamento de dados, em tempo real, gerados a partir de web sites, aplicações e sensores. Essencialmente, o Kafka age como um "sistema nervoso central", que coleta os dados de Big Data, tornando-os disponíveis como um fluxo em tempo real para o consumo de outras aplicações. Funciona com baixa latência, funcionando como um repositório centralizado de fluxo de dados constante.
Producers(fonte de dados) -> Kafka cluster -> Consumer(aplicações consumidoras)
FUNCIONAMENTO passo a passo
Coleta os dados de diversas fontes e gravar no HDFS (Flume ou Sqoop);
Análise dos dados com script personalizado (Pig);
Criar um job MapReduce ou conjunto de jobs e gerenciar o workflow (Oozie);
Gerenciar o cluster Hadoop, para armazenamento e processamento de Big Data (Zookeeper);
Usar ferramenta própria para armazenamento e análise de Big Data (HBase / Hive, ñ própria);
Aplicar Machine Learning (Mahout);
Análise de Big Data em tempo real (Kafka).
Soluções comerciais com Hadoop
Vantagens
A licença do Hadoop é livre, gratuita, porém o suporte, ferramentas personalizadas e profissionalização capacitada é paga, para um melhor uso em soluções empresariais. Empresas modificam e personalizam o Hadoop para um melhor fornecimento de serviços.
AWS Elastic MapReduce (EMR)
Amazon Web Service Elastic MapReduce(EMR) é a uma plataforma de análise de Big Data construída sobre arquitetura HDFS, podendo ser 100% em cloud. Com foco principal em consultas de mapeamento/redução, o AWS EMR explora ferramentas Hadoop, fornecendo uma plataforma de infraestrutura escalável e segura. O pagamento da plataforma é feito por quantidade de uso.
Cloudera
Cloudera, criada por engenheiros do Google, Yahoo e Facebook, está focada em fornecer soluções empresariais do Hadoop, com cluster com mais de 1000 nós, para análise de Petabytes. Cloudera usa produtos 100% Open Source, como Hadoop, Pig, Hive, HBase e Sqoop. Possui o Cloudera Manager, sistema de gestão de Big Data. O Cloudera QuickStart VMs é a versão free do Cloudera Hadoop.
Hortonworks (HDP)
Hortonworks Data Platform(HDP) é uma suite de funcionalidades essenciais para implementação Hadoop, que pode ser usado para qualquer plataforma tecnológica de dados. Apache Ambari é um exemplo de console de gerenciamento de cluster Hadoop, desenvolvido pela Hortonworks.
MapR
MapR Data Platform suporta mais de 20 projetos Open Source. Permite utilização de aplicações baseadas em Hadoop e Spark, suportando processamento de dados em batch ou streaming de dados em tempo real.
Pivotal HD
Pivotal Hadoop(HD) é uma distribuição comercial Hadoop, que consiste em um conjunto de ferramentas ágeis de Big Data e expansão do Hadoop, possuindo capacidade de análise em tempo real e decisões de processos de negócios, que podem ser tomadas quase imediatamente com análise de Big Data. Fornece um motor SQL nativo para o Hadoop, possuindo também suporte a processamento de Big Data em memória, tornando-o mais ágil.
Windows Azure HDInsight
Distribuição Apache Hadoop distribuída em cloud Azure. Azure HDInsight lida com Big Data, possibilitando a inclusão de nodes, sob demanda, ao cluster. Por ser 100% Hadoop, pode processar dados Estruturados, Semi-Estruturados e Não-Estruturados, dos mais variados modelos. Possui extensões para programação em C#, Java e .NET, para gestão de jobs Hadoop. É integrado ao Excel para gestão de dados.
Apache Spark

É um engine rápido de uso geral para processamento de Big Data ao longo de um cluster, desenvolvido com Scala. É similar ao Hadoop MapReduce, usando Hadoop HDFS como base, mas pode ser usado com Cassandra, HBase e MongoDB, podendo, também, ser usado com Python, R, Scala e Java. Surgiu para suprir, com mais desempenho no processamento de queries e algoritmos, além permitir processamento em memória e recuperação de falhas, o Apache MapReduce com a computação iterativa.
- Velocidade: Velocidade de execução 100x mais rápido, em memória, que o Hadoop MapReduce e 10x em disco;
- Facilidade de uso: Aplicações escritas em diferentes linguagens de programação para desenvolvimento de API's de alto nível;
- Generalidade: Combina SQL Streaming e análise complexa, além do uso de ferramentas como Spark SQL(processamento SQL), MLlib(processamento Machine Learning), GraphX(processamento de grafos) e Spark Streaming.
- Integração com Hadoop: Executa sobre o Yarn cluster manager e permite leitura/escrita de dados no HDFS.
Apache Spark Framework
Framework similar ao Hadoop, ou seja, composto por ferramentas que realizam determinadas funções. Entre as ferramentas estão:
- Spark Core: Contém as funcionalidades básicas do Spark, incluindo componentes para agendamento de tarefas, gestão de memória, recuperação de falha e sistemas de armazenamento;
- Spark SQL: Pacote para tarefas de dados estruturados, que permite realizar queries através de linguagem SQL, além de suportar diversas fontes de dados, como Hive e JSON;
- Spark Streaming: Componente para processamento de streams de dados em tempo real;
- Spark MLlib: Biblioteca para Machine Learning;
- Spark GraphX: Biblioteca para manipulação de grafos e computação em paralelo;
- Standalone Scheduler;
- YARN;
- Mesos.
Spark vs Hadoop
O Hadoop é a plataforma original do Big Data em batch(seleção e envio de grandes conjuntos de dados), possibilitando sua análise e processamento. Possui um ecossistema bem definido, que permite entender suas funções, como na utilização do Pig, Hive e HBase. No caso, o MapReduce possui algumas limitações, além do desempenho, que serão supridas com o Spark:
- Programação iterativa(Machine Learning, algoritmos...);
- Streaming de dados.
O Apache Spark é a primeira plataforma de Big Data a integrar batch, streaming e programação iterativa em um único framework.
Hadoop
- Armazenamento distribuído + Computação distribuída;
- Trabalha com framework MapReduce;
- Normalmente processa dados em disco(HDFS);
- Não é ideal para trabalho iterativo;
- Processo batch(MapReduce - Java,Pig,Hive);
- Suporta Java(serve Python, mas traduz internamente à Java);
- Não possui shell unificado.
Spark
- Somente computação distribuída;
- Trabalha com Computação genérica;
- Processa dados em disco e em memória(Spark RDD - Java,Python,Scala,R);
- Excelente para trabalhos iterativos(Machine Learning);
- Até 10x mais veloz em disco, 100x em memória(batch ou streaming);
- Suporta Java, Python, Scala, R;
- Shell para exploração ad-hoc(tudo diretamente via terminal).
Apache Storm
Framework, desenvolvido em Java, para Streaming de Big Data, que se tornou o padrão para processamento em tempo real e em paralelo distribuído de Big Data. Não pertence ao Spark. A gestão do estado do cluster é com o Zookeeper. Entre as vantagens do uso, estão:
- Open Source e fácil;
- Tolerante a falhas, flexível, confiável e suporta diversas linguagens de programação;
- Processa dados em tempo real com muito desempenho.
BD's NoSQL
BDs NoSQL(Not Only SQL / Non-SQL) servem para armazenamento de Big Data, que têm objetivo de armazenar dados Não-Estruturados ou Semi-Estruturados, que os BDs Relacionais não suportam. Oferecem arquitetura mais escalável e flexível do que os Relacionais. Tornou-se popular com o advento das Redes Sociais e IOT. Abaixo, seguem categorias de BD's NoSQL.
Graph Databases
Geralmente é aderente a cenários de rede social online, onde os nós representam as entidades e os laços representam as interconexões entre eles. Desta forma, é possível atravessar o grafo seguindo as relações. Essa categoria tem sido usada para lidar com sistemas de recomendação e listas de controle de acesso, fazendo uso de sua capacidade de ligar com dados altamente interligados. O Neo4j é o maior da categoria.
Document Databases
Permite o armazenamento de milhões de documentos. Por exemplo, armazenar dados sobre um funcionário, assim como seu currículo(como um documento) e relacioná-lo à outros campos específicos no BD. O principal representante dessa categoria é o MongoDB.
Key-value Store
Os dados são armazenados no formato key-value, onde os valores são identificados pelas chaves. É possível armazenar bilhões de registros de forma rápida. O principal exemplo dessa categoria é o Amazon DynamoDB.
Column Family Stores
Também chamados de BD Orientados a Coluna, os dados são organizados em grupos de colunas e tanto o armazenamento, quanto as pesquisas de dados são baseadas em chaves(keys). Os exemplos mais comuns dessa categoria são HBase e Hypertable.
Vantagens de uso:
- Representação de dados sem esquema;
- Tempo de desenvolvimento;
- Velocidade;
- Escalabilidade.
MongoDB
MongoDB é um BD NoSQL Orientado a Documento. Um BD NoSQL Orientado a Documento substitui o conceito de 'linha' dos BDs Relacionais, por um modelo mais flexível, o 'documento'. São algumas das características do MongoDB:
- Indexação: Suporta índices secundários, permitindo a construção de queries mais velozes;
- Agregação: Permite a construção de agregações complexas de dados, otimizando o desempenho;
- Tipos de dados especiais(Próprios): Suporta coleções time-to-live para dados que expiram em um determinado tempo, como sessões por exemplo;
- Armazenamento: Armazenamento de Big Data.
MongoDB
Database, Collection, Document, Field, Embedded Documents, Primary Key
RDBMS
Database, Table, Tuple/Row, Column, Table Join, Primary Key
Onde usar MongoDB
- Big Data;
- Gestão de conteúdo;
- Infraestrutura Social e Mobile;
- Gestão de Dados de Usuários;
- Data Hub.
Apache Cassandra
BD NoSQL, livremente distribuído, de alta performance, extremamente escalável e tolerante a falha. Muito útil para pesquisa de dados indexada. É voltado para trabalhar com clusters, sendo totalmente escalável, ou seja, novos nodes podem ser adicionados, à medida que os dados crescem. Excelente com leitura/escrita.
Apache CouchDB
BD totalmente voltado para web, onde os dados são armazenados no formato JSON, que constituem em campos que podem ser Strings, números, datas, listas e mapas associativos. Suporta aplicativos web e mobile. É distribuído em pares, com um server e um client, que podem ter cópias independentes do mesmo Database. Foi o 1º BD NoSQL, construído com mentalidade de alto desempenho e tolerância a falha. Permite aos usuários armazenar, reproduzir, sincronizar e processar Big Data, distribuídos em dispositivos móveis, servidores, Data Centers e regiões geográficas distintas em qualquer configuração de implantação, incluindo Cloud.
Iniciando um projeto Big Data
É a aplicação de técnicas para análise de dados, a fim de extrair informações de Big Data. Se a empresa trabalha com grandes conjuntos de grande variedade de dados, em alta velocidade, então ela trabalha com Big Data. As manufaturas(indústrias) usam dados dos sensores de suas máquinas, a fim de prever necessidades de manutenção, tempo de vida útil, rotinas de funcionários, defeitos de produção, etc. Com isso, usar Machine Learning para realizar previsões. Na área das finanças, como bancos, financeiras e fundos de investimentos, usam Big Data para gerar Machine Learning em seus produtos e análise de finanças e clientes. Na área de saúde, o Big Data Analytics se encontra para a criação de prontuários eletrônicos, cruzamento de dados a fim de prever informações sobre determinado medicamento e seus efeitos, prever possíveis doenças com os sintomas, tratamentos, criação de IA para segmentação de imagens médicas, etc. O varejo também está muito presente com Big Data ANalytics, pois são imensos os dados, de produtos, vendas, lojas, colaboradores, etc. Isso deve ser analisado, a fim de criar IA com Machine Learning para melhorias em vendas, previsões de mercado, empresas e colaboradores, etc.
Cases diferenciados
- Caesars Entertainment: Companhia de entretenimento de casinos usa Hadoop para identificar diferentes segmentos de consumidor e criar campanhas de marketing específicas para cada um deles. A empresa processa mais 3 milhões de registros/hora;
- Cerner: Empresa de tecnologia para setor de saúde construiu um hub de dados corporativos no CDH(Cloudera Distribution), para criar visão mais compreensível de qualquer paciente, condição ou tendência, que ajuda a monitorar mais de 1 milhão de pacientes diariamente;
- eHarmony: Site de namoro atualizou seu ambiente em Cloud, usando o CDH para analisar Big Data, a fim de combinar perfis mais personalizados;
- MasterCard: Implementou CDH do Hadoop, para integrar conjunto de dados com outras ferramentas parceiras, com o MasterCard Advisors;
- Farmlogs: A companhia de software para gestão de produções agrícolas usa Analytics em tempo real para fornecer informações sobre colheitas, condições de plantio, estado da vegetação para 20% das fazendas americanas;
- Nippon Paint: Uma das maiores fornecedoras de tinta da Ásia usa Analytics para compreender comportamento de clientes, otimizar sua cadeia de suprimentos e melhorar suas campanhas de marketing.
Como iniciar um projeto de Big Data
- Definição de Business Care;
- Planejamento do Projeto;
- Definição dos Requisitos Técnicos;
- Criação de um Total Business Value Assessment.
Definição do Business Care
Antes de iniciar qualquer projeto de Big Data, precisa-se definir os objetivos, ferramentas, métodos que serão utilizados, métricas de avaliação, entre outros pontos do tipo. Tudo isso deve ser claro e documentado em um Business Case, assim como será documentado o andamento do projeto, obstáculos, stakeholders. Isso, para enfim definir os objetivos de alto nível, área problemática atendida primeiro. Esse documento será criado em conjunto com todos os stakeholders, a fim de clarear a Big Picture, visão de alto nível do projeto. Com tudo finalizado, parte-se então para o planejamento do projeto em si.
Planejamento do projeto
Identificar métricas, identificar as questões comerciais, como orçamentos, para tirar o máximo de ganho possível. Determinar requisitos de negócios, e definir como seria a implementação bem sucedida de Big Data, o que é mais complicado, identificar também toda a aprovação de critérios. Precisa-se também determinar o escopo adequado, desenvolver o orçamento geral. Empresas precisam de aproximadamente 9 meses para concluir um projeto de planejamento. Definir ambientes, de homologação, testes, validações, que momento será enviado para ambiente de produção.
Definição dos Requisitos Técnicos
Etapa que faz parte do planejamento do projeto. Criação da arquitetura do projeto, integração de ambientes, como BI e Big Data. Quais os atributos de BDs Relacionais, quais as possíveis fontes de dados, segundo objetivos levantados. Como serão mescladas e armazenar as diferentes fontes de dados, de acordo com seus tipos (trabalhar com bash ou streaming). Quais as ferramentas de análise que serão utilizadas. Quais as habilidades técnicas necessárias e equipe necessária para o projeto. Qual será a arquitetura do projeto, com DataHub ou outro modelo. Quais as ferramentas de reports, linguagens e tecnologias relacionadas.
Criação de um Total Business Value Assessment
O Time to Business, tempo para o projeto gerar resultados, envolve cerca de 3 anos. Esse tempo é estipulado nesta etapa. Definição de questões, como facilidade de uso da aplicação/solução, escalabilidade geral dos dados e processamento e infraestrutura(ambiente em Cloud é mais flexível para o caso). Definição dos padrões a serem utilizados, de forma geral, para a implementação. Definição e análise da maturidade da empresa para tal. Como será o suporte e manutenção, qualificações e treinamentos da empresa.
Spark no Linux
Pré-requisitos:
- Java(Jdk): Via terminal(sudo apt install default-jdk)
- Distro Python(Anaconda): Arquivo .sh(bash arquivo.sh)
Instalar Spark (.tgz):
- Descompactar: sudo tar -xvf nomearquivo.tgz
- Mover para pasta: sudo mv arquivogerado /opt/spark
- Configurar variáveis de ambiente: No diretório home:
sudo nano .bashrc
(dentro do arquivo, no final):
# Variaveis ambientes do Spark
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS=notebook
(salvar e sair do editor (cntrl+x))
source .bashrc
Abrir Pyspark:
pyspark (abrirá no browser)
Criar Novo notebook:
No Pyspark, botão 'new' > Python(default)
Na linha do comando do Pyspark, testar: print(sc)
Elaborado por Mateus Schwede
ubsocial.github.io