===== INTRODUÇÃO =====
Inteligência artificial é a área da ciência da computação responsável pelo desenvolvimento de sistemas que simulem a capacidade humana de resolver problemas. Os principais conceitos/áreas são:
- Inteligência computacional: Redes neurais, computação evolucionária, lógica nebulosa (fuzzy);
- Machine learning (ML, aprendizado de Máquina): Métodos matemáticos para treinar algoritmos;
- Data mining (mineração de dados): Extrair conhecimentos de base de dados, via métodos de machine learning;
- Neural network (rede neural): Tipo de ML, como um algoritmo;
- Deep learning (aprendizado profundo): Muito mais dados e processadores mais potentes (rede neural com muitas camadas);
- Big data: Imenso volume de dados (necessário algoritmos de ML para tratamento dos dados);
- Data analytics (análise de dados): Inspeção, transformação e modelagem de dados, a fim de obter informações e insights sobre;
- Data science (ciência de dados): Exploração e análise de dados (data analytics), envolvendo ciência da computação + estatística, além de ML.

Machine learning
Tipos de ML:- Supervisonada (classificação e regressão);
- Não Supervisonada (associação, agrupamento, detecção de outliers, padrões sequenciais e sumarização);
- Reforço.
- Classificação: Dividir atributos por determinadas classes (rótulos). Ex: pessoas que gostam de rock e pessoas que não gostam de rock;
- Regressão: Previsão realizada através da análise de valores numéricos, como dados históricos. Ex: com base em valores climáticos, medir previsão do tempo.
- Associação: Dados em comum (ex: maior histórico de compra de item x nos sábados);
- Agrupamento: Agrupar dados em comum (ex: grupo de games de ação, grupo de games de terror);
- Detecção de outliers (desvios): Detectar anomalias em grupos de dados (ex: atletas em doping - desempenhando além do normal);
- Descoberta de padrões sequenciais: Detectar relações entre grupos de dados (ex: leitor de Harry Potter tende a gostar de livros de Harry Potter);
- Sumarização: Abstrair dados de um grupo maior, conforme atributos solicitados (ex: BD de clientes, exibir somente cliente maiores de 50 anos);
Aprendizagem supervisionada: Classificar se foto refere-se ao Homer ou Bart Simpson. Fase 1 (treino), extraem-se as características de Homer e Bart (montagem do dataset - tabela com dados), após executa-se algoritmo ML (via supervisor), criando-se padrões de Homer e Bart, então tem-se modelo aprendido (distingue-se fotos de Homer e Bart). Fase 2 (teste), sumete-se foto desconhecida, para modelo distinguir se é Homer ou Bart. Fases treino/teste são denominados validação cruzada.
Aprendizagem não supervisionada: Análise automática dos dados (associação, agrupamento), sem supervisão, nem treinamento prévio (predição). Necessita somente descrição dos dados (descritiva) e análise para determinar significado dos padrões encontrados (verificar se resultados são pertinentes). Ex: se pessoa que compra x também compra y, então pessoas que comprarão x também comprarão y.
Aprendizagem por reforço: Aprender com interações do ambiente (causa e efeito), via experiência própria. Muito utilizada em SMA (sistema multiagente, com vários agentes interagindo no ambiente). Ex: robô automatizado bate em parede e danifica-se. Então, concluirá que deve evitar bater em paredes.
Etapas modelo preditivo:
- Coleta de dados (via BD, CSV, big data, etc);
- Exploração e preparação dos dados (criação do algoritmo para tal);
- Importar bibliotecas;
- Upload do dataset e exploração dos dados brutos;
- Visualização dos atributos ordenadamente e em gráficos, a fim de encontrar relações entre previsores;
- Domain, separação entre previsores(x) e classes(y);
- Tratamento dos dados (valores faltantes, valores inconsistentes(outliers, normalization, standardisation, tipos diferentes));
- Divisão dados treinamento (x_train(previsores), y_train(classes)) e teste (x_test(previsoes) e y_test(classes));
- Criação do algoritmo IA.
- Treinamento do modelo (submeter dados de treinamento (x_train e y_train) ao algoritmo IA);
- Avaliação do modelo (comparar dados submetidos de treinamento (x_train e y_train), com dados de teste (x_test e y_test), para identificar precisão de acerto do algoritmo IA);
- Otimização do modelo (otimizar algoritmo IA, com melhores dados de treinamento, re-verificar precisão do algoritmo IA).
Termos chave:
- Outliers: Dados com muita discrepância de valor (necessário tratamento);
- Normalization: Colocar dados entre intervalo de valores menor, como 0 e 1, ou -1 e 1 (caso haja valores negativos), sem distorcer diferenças nas faixas de valores (diminuir discrepância de valores). Não indicado para corrigir outliers. Ideal para aplicação quando distribuição não é Gaussiana ou desvio padrão é muito pequeno. Garante maior accuracy ao modelo;
- Standardisation: Colocar média dos dados em 0 e o desvio padrão em 1. Melhor utilizado em distribuição Gaussiana. Mais indicado para tratamento de outliers. Garante maior accuracy ao modelo;
- Gráficos, geralmente eixo y (vertical) e eixo x (horizontal). Normalization e standardisation achatam gráfico horizontalmente (eixo x). Remoção de outliers reduzem gráfico verticalmente (eixo y);
- Algoritmos que precisam dos dados na mesma escala: KNN (K-Nearest Neighbours), Redes Neurais, Regressão Linear, Regressão Logística e SVM;
- Algoritmos que não precisam dos dados na mesma escala: Árvores de Decisão, Random Forest, AdaBoost, Naïve Bayes, etc (porém, aconselhável testar a normalização ou padronização);
- Evaluation: Avaliação do algoritmo ML, nível de desempenho (acerto) do modelo;
- LabelLabelEncoder: Tratamento de valores categóricos (string), onde cada tipo de valor no registro será transformado em um número de referência. Problema de somente utilizar LabelEncoder são as inúmeras categorias e valores muito amplos (algoritmo de IA considerará atributo 20 mais importante que 3, pois 20 > 3);
- OneHotEncoder: Tratamento de valores categóricos (string), onde cada tipo de registro (category) receberá um nº identificador (do tipo Dummy), de acordo com a quantidade de tipos de registros neste atributo (Ex: carros Gol, Pálio e Uno: 3 tipos de registros do atributo 'carro', então Gol = 100, Pálio = 010 e Uno = 001).
- ConfusionMatrix: Matriz de confusão (matriz de erro) é tabela (contingência 2x2 especial) que permite visualização do desempenho do algoritmo de classificação. Bidimensional: 2 dimensões ("real" e "prevista"), onde linhas (eixo x) são instâncias de uma classe prevista, e colunas (eixo y) são instâncias da classe real;
- Exemplo: sendo 0 não chove, e 1 chove, tem-se reais = [1,0,1,0,0,0,1,0,1,0] e preditos = [1,0,0,1,0,0,1,1,1,0];
- Frequência verdadeiro positivo (true positive - TP): Classe buscada prevista corretamente no conjunto real. Ex: quando realmente chove e o modelo previu corretamente que chove;
- Frequência falso positivo (false positive - FP): Classe buscada prevista incorretamente no conjunto real. Ex: quando realmente não chove, mas modelo previu que chove;
- Frequência falso verdadeiro/Verdadeiro negativo (true negative - TN): Classe não buscada prevista corretamente no conjunto real. Ex: realmente não chove e o modelo previu corretamente que não chove;
- Frequência falso negativo (false negative - FN): Classe não buscada prevista incorretamente no conjunto real. Ex: realmente chove e o modelo previu que não chove.
- Exemplo 2: sendo 0 não chove, e 1 chove, tem-se eais = [1,0,1,0,0,0,1,0,1,0] e preditos = [1,0,0,1,0,0,1,1,1,0]
- Previu chove 3 vezes corretamente;
- Previu não chove 4 vezes corretamente;
- Previu chove 1 vez incorretamente;
- EM CONSTRUÇÃO
===== CLASSIFICAÇÃO =====
Conforme exemplo análise de risco de crédito. Cada registro (linha) possui atributos (colunas) previsores (características) e atributos classe (resultado). Na aprendizagem supervisionada, a classe sempre é conhecida.
- Atributos previsores (variáveis dependentes): Histórico de crédito (bom, ruim, desconhecido), dívida (baixa, alta), garantias (nenhuma, adequada), renda anual (menor que 15 mil, entre 15 mil e 35 mil, maior que 35 mil);
- Atributos meta/classe (variáveis independentes): risco (baixo, moderado, alto).
| Histórico de crédito | Dívida | Garantias | Renda anual | Risco |
|---|---|---|---|---|
| Ruim | Alta | Nenhuma | Menos de 15 mil | Alto |
| Desconhecido | Baixo | Nenhuma | Entre 15 mil e 35 mil | Moderado |
| Desconhecido | Baixo | Adequada | Maior que 35 mil | Baixo |
----- Pré-processamento de dados -----
Variáveis numéricas:- contínua: nºs reais (temperatura 30.2);
- discreta: conjunto finito, valores inteiros (preços [12,4,6], idade 25);
- nominal: dados não mensuráveis, sem ordenação (gênero);
- ordinal: dados ordenados categorizados (tamanhos p,m,g). Convertidas para discretas via categorias numéricas (p=1,m=2,g=3)
import pandas as pd #gerenciar csv
import numpy as np #computação científica
import seaborn as sns #gráficos
import matplotlib.pyplot as plt #gráficos
import plotly.express as px
Dataset risco de crédito (credit data)
Objetivo da IA é informar se cliente, conforme condições, pagará (default 0) ou não (default 1) o crédito.
| clientid | income | age | loan | default | |
|---|---|---|---|---|---|
| 0 | 1 | 66155.925095 | 59.017015 | 8106.532131 | 0 |
| 4 | 5 | 66952.688845 | 18.584336 | 8770.099235 | 1 |
2. Exploração dos dados:
base_credit = pd.read_csv('/content/credit_data.csv') #upload do arquivo CSV (atente-se ao local do upload '/content/')
base_credit #ver dados
base_credit_head(10) #ver 10 primeiros dados
base_credit.tail(8) #ver 8 últimos dados
base_credit.describe() #mostrar, para cada atributo numérico: count (quantidade total), mean (média), sid (desvio padrão - variação/afastamento dos dados em relação ao valor da média), min/25%/50%/75%/max (quartis - valores mínimos/percentuais/máximos)
base_credit[base_credit['income'] == 1000.00] #mostrar pessoa com renda 1000.00
base_credit[base_credit['loan'] >= 1.377] #mostrar pessoa com dívida menor ou igual a 1.377
3. Visualização em gráficos:
np.unique(base_credit['default']) #mostrar tipos de valores do 'default'
np.unique(base_credit['default'], return_counts=True) #quantidades de valores do 'default'
sns.countplot(x = base_credit['default']); #gráfico de contagem (img1)
plt.hist(x = base_credit['age']); #histograma intervalos de 'age' (img2)
plt.hist(x = base_credit['income']); #histograma 'income' (img3)
plt.hist(x = base_credit['loan']); #histograma 'loan' (img4)
grafico = px.scatter_matrix(base_credit, dimensions=['age','income','loan'], color='default') #gráfico scatter (dispersão), combina atributos conforme 'default' (coloração interna)
grafico.show()
")
")
")
")

4.1. Tratamento de valores inconsistentes:
base_credit.loc[base_credit['age'] < 0] #ver dados com idades negativas
#apagar coluna inteira do dado inconsistente
base_credit2 = base_credit.drop('age', axis=1) #axis0 é linha e axis1 é coluna
base_credit2
base_credit.index #index é o id do dado
base_credit[base_credit['age'] < 0].index
#apagar células de dados inconsistentes
base_credit3 = base_credit.drop(base_credit[base_credit['age'] < 0].index)
base_credit3
base_credit3.loc[base_credit3['age'] < 0] #dados removidos
#preencher dados inconsistentes manualmente, com média
base_credit.mean() #localizar média de valores (ou base_credit['age'].mean())
base_credit['age'][base_credit['age'] > 0].mean() #média não considerando negativos
base_credit.loc[base_credit['age'] < 0, 'age'] = 40.92 #preencher idades negativas com média de idades
base_credit.loc[base_credit['age'] < 0] #verificar se há idades negativas
4.2. Tratamento de valores faltantes:
base_credit.isnull() #verificar se há dados faltantes (true é faltante)
base_credit.isnull().sum() #quantidade de dados faltantes
base_credit.loc[pd.isnull(base_credit['age'])] #linhas com idade faltante
#preencher valores faltantes com média
base_credit['age'].fillna(base_credit['age'].mean(), inplace=True) #preencher com média
base_credit.loc[pd.isnull(base_credit['age'])] #verificar se há idades faltantes
base_credit.loc[(base_credit['clientid']==29) | (base_credit['clientid']==31) | (base_credit['clientid']==32)]
base_credit.loc[base_credit['clientid'].isin([29,31,32])]
5. Separação entre previsores e classes:
x armazena previsores (income, age, loan) e y armazena classe (default). Geralmente id's são descartados.
X_credit = base_credit.iloc[:,1:4].values #':' seleciona todas linhas do dataset, '1:4' seleciona 1 até 3
y_credit = base_credit.iloc[:, 4].values #somente coluna 4
X_credit #ver conteúdo da variável ('y_credit' ver y, 'type(X_credit)' ver tipo)
6. Escalonamento dos atributos:
Quando discrepância de valores do dataset é muito grande, deve-se deixá-los na mesma escala, via padronização.
- Padronização(standardisation): x = ((x-media(x)) / desvioPadrao(x))
- Normalização(normalization): x = ((x-min(x)) / (max(x)-min(x)))
X_credit[:,0].min(), X_credit[:,1].min(), X_credit[:,2].min() #selecionar valores mínimos de cada atributo
X_credit[:,0].max(), X_credit[:,1].max(), X_credit[:,2].max() #Selecionar valores máximos de cada atributo
from sklearn.preprocessing import StandardScaler #library para ML, StandardScaler fará padronização
scaler_credit = StandardScaler()
X_credit = scaler_credit.fit_transform(X_credit)
X_credit[:,0].min(), X_credit[:,1].min(), X_credit[:,2].min() #valores padronizados (não há problema de valores negativos, pois considera-se uso da média e desvio padrão)
X_credit[:,0].max(), X_credit[:,1].max(), X_credit[:,2].max()
X_credit
Datacet censo
Objetivo da IA é informar se pessoa, conforme condições, ganhará ou não mais que 50mil por ano (income).
| age | workclass | final-weight | education | education-num | marital-status | occupation | relationship | race | sex | capital-gain | capital-loos | hour-per-week | native-country | income | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 39 | State-gov | 77516 | Bachelors | 13 | Never-married | Adm-clerical | Not-in-family | White | Male | 2174 | 0 | 40 | United-States | <=50K |
| 32556 | 27 | Private | 257302 | Assoc-acdm | 12 | Married-civ-spouse | Tech-support | Wife | White | Female | 0 | 0 | 38 | United-States | <=50K |
| 32557 | 40 | Private | 154374 | HS-grad | 9 | Married-civ-spouse | Machine-op-inspct | Husband | White | Male | 0 | 0 | 40 | United-States | >50K |
2. Exploração dos dados:
base_census = pd.read_csv('/content/census.csv')
base_census48.000000
base_census.describe()
base_census.isnull().sum() #verificar se há valores faltantes
3. Visualização em gráficos:
np.unique(base_census['income'], return_counts=True)
sns.countplot(x = base_census['income']); #gráfico de barras (img1)
plt.hist(x = base_census['age']); #histograma de idades (img2)
plt.hist(x = base_census['education-num']); #histograma de anos estudados (img3)
plt.hist(x = base_census['hour-per-week']); #histograma de horas trabalhadas por semana (img4)
grafico = px.treemap(base_census, path=['workclass','age'])
grafico.show() #gráficos agrupamentos entre classe de trabalho e idade (img5)
grafico = px.treemap(base_census, path=['occupation','relationship','age'])
grafico.show() #gráficos agrupamentos entre ocupação, relacionamento e idade (img6)
grafico = px.parallel_categories(base_census, dimensions=['occupation','relationship'])
grafico.show() #gráfico categorias paralelas entre ocupação e relacionamento (img7)
grafico = px.parallel_categories(base_census, dimensions=['workclass','occupation','income'])
grafico.show() #gráfico categorias paralelas entre classe de trabalho, ocupação e renda (img8)
grafico = px.parallel_categories(base_census, dimensions=['education','income'])
grafico.show() #gráfico categorias paralelas entre educação e renda (img9)
")
")
")
")
")
")
")
")
")
4. Separação entre previsores e classes:
base_census.columns
X_census = base_census.iloc[:,0:14].values #criar variável previsores (age à native-country)
X_census #X_census[0]
y_census = base_census.iloc[:,14].values #criar variável classe (income)
y_census
5.1. Tratamento de atributos categóricos (LabelEncoder):
Transformar dados texto em numéricos. LabelEncoder transformará cada dado em nº de referência.
from sklearn.preprocessing import LabelEncoder
label_encoder_teste = LabelEncoder()
X_census[:,1]
teste = label_encoder_teste.fit_transform(X_census[:,1])
teste #cada tipo do workclass será nº de referência (private é 4, state-gov é 7, etc)
X_census[0]
#transformar cada atributo
label_encoder_workclass = LabelEncoder()
label_encoder_education = LabelEncoder()
label_encoder_marital = LabelEncoder()
label_encoder_occupation = LabelEncoder()
label_encoder_relationship = LabelEncoder()
label_encoder_race = LabelEncoder()
label_encoder_sex = LabelEncoder()
label_encoder_country = LabelEncoder()
#aplicar LabelEncoder em cada atributo categórico
X_census[:,1] = label_encoder_workclass.fit_transform(X_census[:,1])
X_census[:,3] = label_encoder_education.fit_transform(X_census[:,3])
X_census[:,5] = label_encoder_marital.fit_transform(X_census[:,5])
X_census[:,6] = label_encoder_occupation.fit_transform(X_census[:,6])
X_census[:,7] = label_encoder_relationship.fit_transform(X_census[:,7])
X_census[:,8] = label_encoder_race.fit_transform(X_census[:,8])
X_census[:,9] = label_encoder_sex.fit_transform(X_census[:,9])
X_census[:,13] = label_encoder_country.fit_transform(X_census[:,13])
X_census[0]
X_census
5.2. Tratamento de atributos categóricos (OneHotEncoder):
LabelEncoder pode criar inúmeras categorias amplas. OneHotEncoder cada registro (categoria) recebe id tipo Dummy, conforme quantidade de tipos específicos de registros.
len(np.unique(base_census['workclass'])) #9 categorias diferentes
len(np.unique(base_census['occupation'])) #15 categorias diferentes
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
onehotencoder_census = ColumnTransformer(transformers=[('OneHot', OneHotEncoder(), [1,3,5,6,7,8,9,13])], remainder='passthrough') #passthrough não exlcui demais atributos com categorias repetidas
X_census = onehotencoder_census.fit_transform(X_census).toarray() #recriar dataset tratado
X_census #X_census[0]
X_census.shape #resultante da soma das quantidades de colunas de cada categoria, de cada atributo
6. Escalonamento dos atributos:
from sklearn.preprocessing import StandardScaler
scaler_census = StandardScaler()
X_census = scaler_census.fit_transform(X_census)
X_census[0] #converter atributos numéricos para mesmo formato
Introdução a avaliação de algoritmos
Levando em conta o exemplo da base de dados Risco de Crédito, o algoritmo de IA analisará os atributos previsores, juntamente com seus respectivos dados, gerando assim o Modelo do Algoritmo, como, por exemplo, um algoritmo Naïve Bayes criará uma tabela de probabilidade, para que, quando quiser classificar registros, utilizará estimativa da probabilidade de cada classe (Ex: Probabilidade da classe Risco alto, moderado e baixo). Um algoritmo de Árvore de Decisão, conforme dados analisados, construirá árvore de decisão, que será percorrida cada vez para identificar a decisão, onde tal nó final será a classe.
Após isso, para fazer a classificação de novos registros à base de dados, submete-se o mesmo para o Modelo do Algoritmo e gerará, com isso, a resposta da classificação. Para sabe a classe que ao qual o registro será classificado, tem-se a base de dados de treinamento e a base de dados de teste, onde, em ambas, a classe de resultado já está informada e os registros são bem diferentes quando comparados uma a outra (Nunca pode testar o algoritmo com os mesmos registros de seu treinamento). Então, submete-se a base de dados do treinamento ao algoritmo (Base de dados de treinamento sempre é bem maior que a de teste), onde o algoritmo gerará o Modelo. Após isso, testa-se o algoritmo conferindo seus resultados com a base de dados de teste (Base bem diversificada, para a maioria de possibilidades em teste).
Com o teste pronto, o supervisor saberá identificar, usando como base os registros de teste, quantos o algoritmo acertou e errou (Ex: O 1º registro está classificado na base de teste como alto, e o algoritmo identificou como Alto (Acerto). O 2º registro está classificado na base de teste como Moderado, e o algoritmo identificou como Baixo (Erro)). Assim, medindo acertos/erros em percentuais, tem-se a medição da eficiência do algoritmo de IA.
7. Divisão das bases em treinamento e teste:
from sklearn.model_selection import train_test_split
#Dividir base Risco de Crédito
X_credit_treinamento, X_credit_teste, y_credit_treinamento, y_credit_teste = train_test_split(X_credit,y_credit,test_size = 0.25,random_state = 0) #X: previsores e Y: classe. Tamanho da base de Teste será 0.25 (75% da base de dados para treinar, 25% para testar), random_state para manter registros de trainamento/teste e consguir compará-los
X_credit_treinamento.shape #1500 registros previsores para treinamento, 3 colunas (income,age,loan)
y_credit_treinamento.shape #1500 registros classe, somente coluna default
X_credit_teste.shape, y_credit_teste.shape #25% dos dados total para cada variável da base teste (X previsores, Y respostas/classe)
#Dividir base Censo
X_census_treinamento, X_census_teste, y_census_treinamento, y_census_teste = train_test_split(X_census,y_census,test_size = 0.15,random_state = 0) #85% dos registros para base Treinamento, 15% para base Teste
X_census_treinamento.shape, y_census_treinamento.shape #27676 registros previsores, 108 colunas. 27676 registros de resposta/classe
X_census_teste.shape, y_census_teste.shape #4855 registros previsores, 108 colunas. 4855 registros de resposta/classe
Salvar bases:
import pickle
#Salvar em disco, wb (Write): Criará arquivos 'credit.pkl' e 'census.pkl'
with open('credit.pkl', mode='wb') as f:
pickle.dump([X_credit_treinamento, y_credit_treinamento, X_credit_teste, y_credit_teste], f)
with open('census.pkl', mode='wb') as f:
pickle.dump([X_census_treinamento, y_census_treinamento, X_census_teste, y_census_teste], f)
----- Naïve Bayes -----
Algoritmo bastante utilizado em mineração de texto (Filtragem de spam, emoção do narrador com relação à sua frase, separação de documentos, etc), baseado em probabilidade (Teorema de Bayes). Usando o exemplo da Base de Crédito, o algoritmo criará a tabela de probabilidade (Conforme abaixo), baseado no histórico de dados. Na tabela, o Risco de Crédito é o atributo Classe. A cada nova submissão para descobrir qual o risco de crédito, os atributos previsores deverão ser submetidos à essa tabela
Montagem da tabela de probabilidade:
Para tal, precisa-se fazer a contagem do risco, onde a classe (Risco de Crédito) fica à esquerda superior, seguida de seus atributos. Conforme histórico de 14 ítens, tem-se 6 considerados 'Alto' (6/14), 3 'Moderado' e 5 'Baixo'. Baseando-se no Risco de Crédito, tem-se 5 'Boa', 5 'Desconhecida' e 4 'Ruim'. Com isso, intercalando os valores nas intersecções, analisa-se quantas vezes tem-se História de crédito 'Boa' e Risco 'Alto' (1/6, onde 1 é 'Boa' e 'Alto', e 6 o valor total de 'Altos'), seguindo respectivamente, para os demais atributos nessa mesma lógica. Então, a soma de todos os numeradores preenchidos deve ser igual ao valor total no valor da classe na situação em questão (5 'Boa', conforme tabela). Na mesma lógica, a soma dos numeradores para cada valor do atributo da classe, com relação ao seu valor total naquela situação, deve ser a mesma com seu valor total (6 'Alto', conforme tabela).
| História do Crédito | Dívida | Garantias | Renda anual | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Risco de crédito 14 |
Boa 5 |
Desconhecida 5 |
Ruim 4 |
Alta 7 |
Baixa 7 |
Nenhuma 11 |
Adequada 3 |
<15000 3 |
>=15000 a <=35000 4 |
>35000 7 |
| Alto 6/14 |
1/6 | 2/6 | 3/6 | 4/6 | 2/6 | 6/6 | 0/6 | 3/6 | 2/6 | 1/6 |
| Moderado 3/14 |
1/3 | 1/3 | 1/3 | 1/3 | 2/3 | 2/3 | 1/3 | 0/3 | 2/3 | 1/3 |
| Baixo 5/14 |
3/5 | 2/5 | 0/5 | 2/5 | 3/5 | 3/5 | 2/5 | 0/5 | 0/5 | 5/5 |
| História do Crédito | Dívida | Garantias | Renda anual | Risco |
|---|---|---|---|---|
| Ruim | Alta | Nenhuma | <15000 | Alto |
| Desconhecida | Alta | Nenhuma | >=15000 a <=35000 | Alto |
| Desconhecida | Baixa | Nenhuma | >=15000 a <=35000 | Moderado |
| Desconhecida | Baixa | Nenhuma | >35000 | Alto |
| Desconhecida | Baixa | Nenhuma | >35000 | Baixo |
| Desconhecida | Baixa | Adequada | >35000 | Baixo |
| Ruim | Baixa | Nenhuma | <15000 | Alto |
| Ruim | Baixa | Adequada | >35000 | Moderado |
| Boa | Baixa | Nenhuma | >35000 | Baixo |
| Boa | Alta | Adequada | >35000 | Baixo |
| Boa | Alta | Nenhuma | <15000 | Alto |
| Boa | Alta | Nenhuma | >=15000 a >= 35000 | Moderado |
| Boa | Alta | Nenhuma | >35000 | Baixo |
| Ruim | Alta | Nenhuma | >=15000 a <=35000 | Alto |
Na prática:
Análise de risco de crédito para novo cliente com os dados (História de crédito: Boa, Dívida: Alta, Garantias: Nenhuma, Renda: >35000). Nesse caso, usa-se, do histórico na tabela, somente as colunas pertinentes ao exemplo atual (História de crédito somente 'boa' - descarta-se Desconhecida e Ruim, Dívida somente 'alta', Garantias somente 'nenhuma' e Renda Anual somente '>35000'). Para o cálculo da probabilidade em cada classe, usa-se a fórmula: 'Multiplicar, nas células pertinentes, todas as frações na mesma linha'.
- Probabilidade risco de crédito Alto: 6/14 * 1/6 * 4/6 * 6/6 * 1/6 = 0,0079
- Probabilidade risco de crédito Moderado: 3/14 * 1/3 * 1/3 * 2/3 * 1/3 = 0,0052
- Probabilidade risco de crédito Baixo: 5/14 * 3/5 * 2/5 * 3/5 * 5/5 = 0,0514
- Percentual Alto: (0,0079 / (0,0079+0,0052+0,0514)) * 100 = 12,24 %
- Percentual Moderado: (0,0052 / (0,0079+0,0052+0,0514)) * 100 = 8,06 %
- Percentual Baixo: (0,0514 / (0,0079+0,0052+0,0514)) * 100 = 79,68 %
- Conclusão: Risco de crédito Baixo
Correção Laplaciana:
Para possibilitar cálculos de probabilidades, como acima, onde possuam fatores 0 para a multiplicação (Exemplo 0/6), adiciona-se 1 ao numerador zerado (1/6), +1 ao total e, portanto, +1 ao denominador em todas as células da tabela com esse caso (0/6 -> 1/7). Além disso, aumenta-se 1 no total do valor do atributo da classe (Antes total de Ruim eram 4, agora Ruim serão 5). Portanto, o ideal nesses casos é realizar a modificação antes da criação da tabela de probabilidades, para facilitação futura dos cálculos. Exemplo de nova submissão de Risco de Crédito (História de Crédito: Ruim, Dívida: Alta, Garantias: Adequada, Renda: <15000).
- Probabilidade risco de crédito Baixo: 5/14 * 0/5 * 2/5 * 2/5 * 0/5
- A partir de agora, serão no Total 5 'História de Crédito Ruim' (Antes 4), 4 'Garantias Adequada' (Antes 3) e 4 'Renda Anual <15000 (Antes 3)'. O total de registros passa a ser 15 (Antes 14). Risco de Crédito Alto passa a ser 7/15 (Antes 6/14). Risco de Crédito Moderado passa a ser 4/15 (Antes 3/14). Risco de Crédito Ruim passa a ser 6/15 (Antes 5/14). Todos os demais denominadores nestas linhas são acrescidos em 1.
- Probabilidade risco de crédito Baixo (Laplaciana): 6/15 * 1/6 * 2/6 * 2/6 * 1/6
Probabilidades Apriori / Posteori:
Supondo-se que hajam 12 ítens (Exemplo dados de histórico de crédito), sendo 5 de classe azul (5/12) e 7 de classe vermelha (7/12) - Probabilidade Apriori. Ao submeter novo ítem em meio aos demais, para descobrir sua provável classe, é realizado, ao seu redor próximo, uma circunferência com um raio traçado (Radius), onde será estimada essa probabilidade inicial do mesmo. Exemplo: Novo ítem dentro de circunferência está entre 3 vermelhas e 1 azul. A probabilidade do ítem ser vermelho é 3/7 e de ser azul é 1/5 (Também Probabilidade Apriori). Neste caso, para verificar a probabilidade final (Probabilidade Posteori):
- Probabilidade vermelha: 7/12 * 3/7 = 0,25
- Probabilidade azul: 5/12 * 1/5 = 0,08
Vantagens e Desvantagens:
Entre as vantagens ao escolher o cálculo Bayes ao invés dos demais, tem-se rapidez, simplicidade de interpretação, trabalha com altas dimensões (Muitos atributos), boas previsões em bases pequenas (Bases em torno de 400 registros). Como desvantagem, os casos trabalham com combinação de características (Atributos independentes), onde cada par de características são independentes (Atributos não se relacionam), o que nem sempre é verdade.
Base de Dados (Risco de Crédito - Pequena)
Aplicação de Naïve Bayes para classificação de Risco de Crédito - Modelo teste.
8. Aplicar algoritmo ML:
from sklearn.naive_bayes import GaussianNB #Importar library Naïve Bayes
A library sklearn deixou de mostrar a tabela de probabilidades construída automaticamente. Mas linguagens como R há a possibilidade.
base_risco_credito = pd.read_csv('/content/risco_credito.csv') #Upload do arquivo CSV com 14 registros de exemplo
base_risco_credito
X_risco_credito = base_risco_credito.iloc[:, 0:4].values #Armazenará atributos previsores (História, dívida, garantias e renda)
X_risco_credito
y_risco_credito = base_risco_credito.iloc[:, 4].values #Armazenará a classe (Risco)
y_risco_credito
#Converter os atributos categóricos String para numéricos:
from sklearn.preprocessing import LabelEncoder
label_encoder_historia = LabelEncoder()
label_encoder_divida = LabelEncoder()
label_encoder_garantia = LabelEncoder()
label_encoder_renda = LabelEncoder()
X_risco_credito[:,0] = label_encoder_historia.fit_transform(X_risco_credito[:,0])
X_risco_credito[:,1] = label_encoder_divida.fit_transform(X_risco_credito[:,1])
X_risco_credito[:,2] = label_encoder_garantia.fit_transform(X_risco_credito[:,2])
X_risco_credito[:,3] = label_encoder_renda.fit_transform(X_risco_credito[:,3])
X_risco_credito
#Para essa base específica, a fim de teste, não será aplicado OneHotEncoder
#Salvar dados em arquivo 'risco_credito.pkl':
import pickle
with open('risco_credito.pkl', 'wb') as f:
pickle.dump([X_risco_credito, y_risco_credito], f)
#Criar e treinar Naïve Bayes para classificação:
naive_risco_credito = GaussianNB()
naive_risco_credito.fit(X_risco_credito, y_risco_credito) #Gerará tabela de probabilidades
#Testar previsão com 2 novos dados:
DADO 1, conforme subtítulo 'Na prática' acima: história boa(0), dívida alta(0), garantias nenhuma(1), renda > 35(2) = Risco de crédito Baixo(79,68 %)
DADO 2, conforme subtítulo 'Laplaciana' acima: história ruim(2), dívida alta(0), garantias adequada(0), renda < 15(0)
previsao = naive_risco_credito.predict([[0,0,1,2],[2,0,0,0]])
previsao #Retornará o resultado das previsões (Baixo e Moderado)
#Informações adicionais:
naive_risco_credito.classes_ #Mostrar tipos de valores da classe
naive_risco_credito.class_count_ #Quantidade de cada tipo de valor
naive_risco_credito.class_prior_ #Mostrar probabilidades Apriori
Base de Dados (Risco de Crédito - credit data)
Aplicação de Naïve Bayes para classificação de Risco de Crédito.
#Importar library e fazer upload do arquivo 'credit.pkl' com os dados:
import pickle
with open('credit.pkl', 'rb') as f:
X_credit_treinamento, y_credit_treinamento, X_credit_teste, y_credit_teste = pickle.load(f)
X_credit_treinamento.shape, y_credit_treinamento.shape #Mostrar registros do histórico
X_credit_teste.shape, y_credit_teste.shape #Mostrar registros que serão submetidos após treinamento
#Criar e treinar Naïve Bayes para classificação:
naive_credit_data = GaussianNB()
naive_credit_data.fit(X_credit_treinamento, y_credit_treinamento)
Testar previsão com valores para teste:
previsoes = naive_credit_data.predict(X_credit_teste)
previsoes #Previsões do algoritmo (0 para Pagou e 1 para Não Pagou)
y_credit_teste #Resposta reais e corretas (Para comparar se as do algoritmo ficarão idênticas, precisão das previsões do algoritmo)
Comparar respostas do algoritmo com reais (Precisão de acertos nas previsões):
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
accuracy_score(y_credit_teste, previsoes) #1º parâmetro são as respostas reais, 2º são as previsões do algoritmo. Mostrará percentual de acertos (0,938 - 93,8%)
confusion_matrix(y_credit_teste, previsoes) #Mostrará matriz de acertos classe por classe ([Linha zero(clientes que pagam classificados como 0 - corretamente),(clientes que pagam classificados como 1 - incorretamente)].[Linha 1(clientes que não pagam classificados como 0 - incorretamente),(clientes que não pagam classificados como 1 - corretamente)])
Graficamente, a matrix de confusão mostra Eixo Y(vertical) o valor real, e no Eixo X(horizontal) o valor da previsão
#Preparo, treinamento e verificação com outra library:
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(naive_credit_data)
cm.fit(X_credit_treinamento, y_credit_treinamento)
cm.score(X_credit_teste, y_credit_teste) #Mostrará a mesma matriz de acertos citada acima, mais organizada visualmente
#Mostrar outros detalhes extras:
print(classification_report(y_credit_teste, previsoes))
Recall: Percentual de acerto das previsões do algoritmo após dados reais
Precision: Percentual de acerto das previsões do algoritmo antes das mesmas ocorrerem na realidade
Como conclusão, teve-se muitos clientes não pagadores classificados, pelo algoritmo, como pagadores (Erroneamente). Os 93,8% de precisão devem-se devido ao alto número de acertos em clientes pagadores classificados como pagadores
Base de Dados (Censo)
Aplicação de Naïve Bayes para classificação de valor salarial.
#Upload do arquivo com dados
with open('census.pkl', 'rb') as f:
X_census_treinamento, y_census_treinamento, X_census_teste, y_census_teste = pickle.load(f)
#Ver qtde de registros e atributos, e respostas (Base treino e teste)
X_census_treinamento.shape, y_census_treinamento.shape
X_census_teste.shape, y_census_teste.shape
#Criar e treinar Naïve Bayes para classificação:
naive_census = GaussianNB()
naive_census.fit(X_census_treinamento, y_census_treinamento)
previsoes = naive_census.predict(X_census_teste)
previsoes
#Comparar previsões com respostas reais:
y_census_teste #Várias previsões erradas (Accuracy de 47%, pois são somente 2 classes no algoritmo, proporcionando maior probabilidade de erro: 50%-50%)
accuracy_score(y_census_teste, previsoes)
cm = ConfusionMatrix(naive_census)
cm.fit(X_census_treinamento, y_census_treinamento)
cm.score(X_census_teste, y_census_teste)
print(classification_report(y_census_teste, previsoes))
Não executar o escalonamento no início do tratamento dos dados proporcionará, nesse caso, maior accuracy
----- Árvore de decisão (decision tree) -----
Também conhecida como CART (Classification and Regression Trees), consiste em gerar, recursivamente, árvore de possibilidades (IF's), onde a classificação de submissões traça o caminho na árvore, até chegar à conclusão (Nó folha), ou seja, o atributo classe de resposta previsto. Em alguns casos, o próprio algoritmo dispensa alguns atributos, considerados não pertinentes para a previsão. Serão elencados, ordenadamente, os atributos com maior importância até os de menor importância, sendo esse ordenamento a conclusão gerada através dos treinamentos do algoritmo. Entre as vantagens de utilizar Árvore de Decisão, tem-se a dispensa de normalização e padronização dos atributos. Como desvantagens, tem-se casos de geração de Árvores muito complexas (Ramos muito específicos - overfitting), problema NP-completo (Complexo) para construir a Árvore, e tal algoritmo é bastante antigo (Usado nos anos 90. Com o passar dos anos, foram aplicadas melhorias, como Random Forest (Florestas Randômicas) para melhor desempenho).
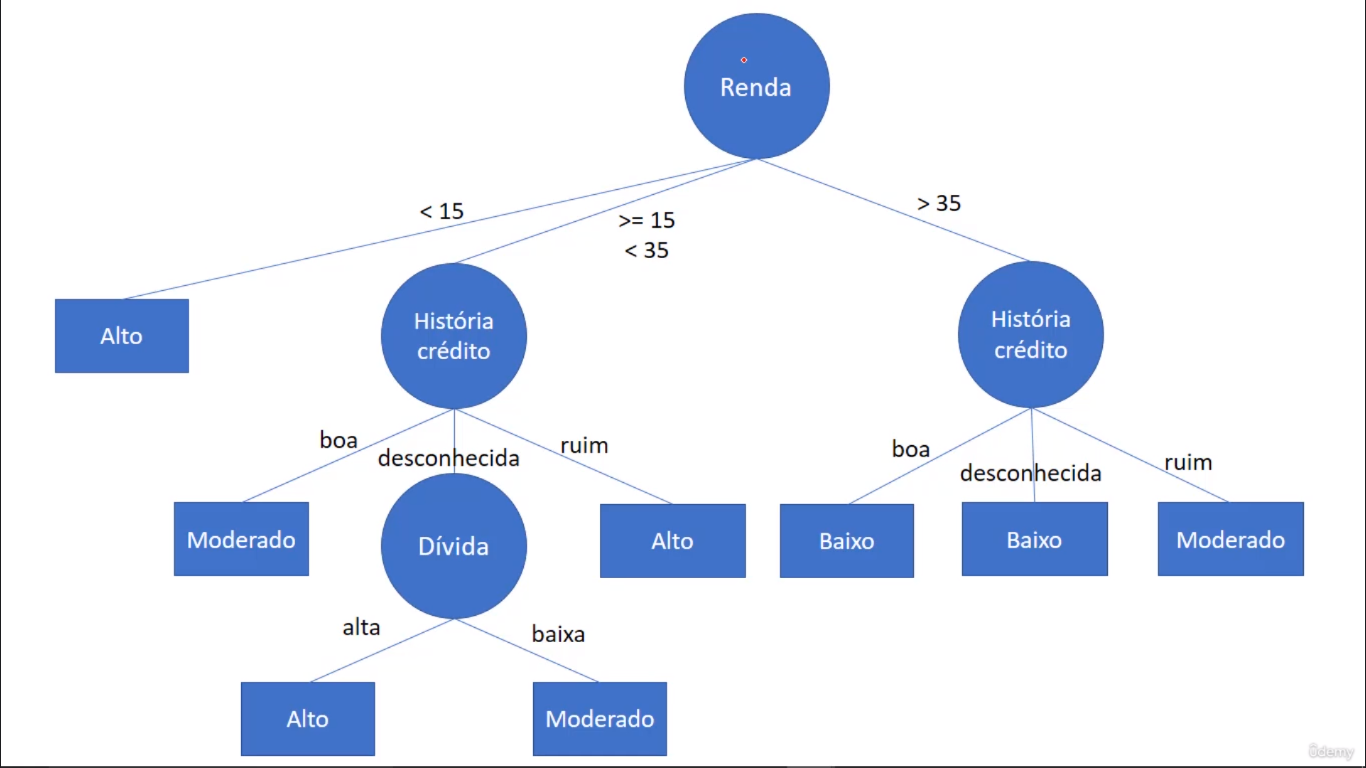
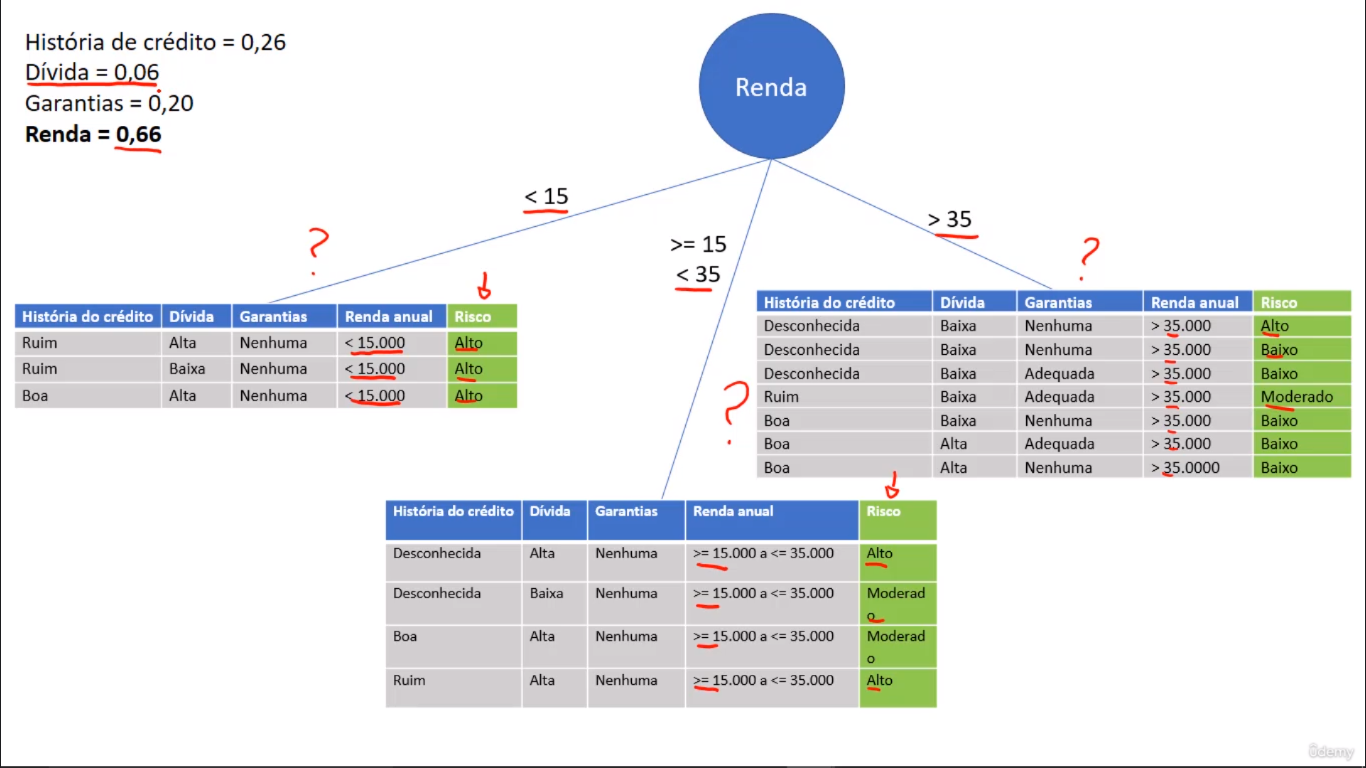
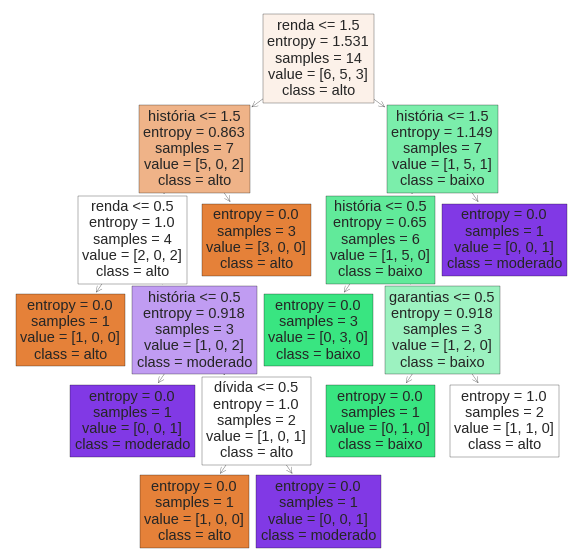
A construção da árvore é baseada nas fórmulas da Entropy (Entropia) e Gain (Ganho de informação), ou seja, é através desses 2 cálculos define-se a pertinência dos atributos para posterior ordenamento na árvore. Utilizando como exemplo os dados da base de risco de crédito (Aqui). Nela tem-se (Alto=6/14), (Moderado=3/14) e (Baixo=5/14). Tais dados são colocados na fórmula da Entropia, a fim de medir o quão organizados/desorganizados os dados estão na sua respectiva base de dados. No caso, a Entropia Geral é de 1,53. Com isso, calcula-se os Ganhos de Informação (G) de todos atributos envolvidos, onde o resultado será o nível de pertinência dos mesmos. Quanto menor o valor da Entropia do atributo, melhor será a distribuição dos dados, ou seja, mais fácil/claro, estatisticamente, para classificar o registro. Atributos com valor de Ganho de Informação baixo tendem a serem excluídos da árvore (Como, no exemplo em questão, a dívida). Abaixo dos cálculos, segue imagem com exemplo visual da construção parcial da árvore.
-
Entropia:
- Entropia Geral: E(s) = -6/14 * log(6/14;2) -3/14 * log(3/14;2) -5/14 * log(5/14;2) = 1,53
- História do crédito: 14 é quantidade de registros (Boa=5/14 (Alto=1/5;Moderado=1/5;Baixo=3/5)), (Desconhecida=5/14 (Alto=2/5;Moderado=1/5;Baixo=2/5)), (Ruim=4/14 (Alto=3/4;Moderado=1/4;Baixo=0/4))
- Dívida: 14 é a quantidade de registros (Alto=7/14 (Alto=4/7;Moderado=1/7;Baixo=2/7)), (Baixa=7/14 (Alto=2/7;Moderado=2/7;Baixo=3/7))
- Garantias: 14 é a quantidade de registros (Nenhuma=11/14 (Alto=6/11;Moderado=2/11;Baixo=3/11)), (Adequada=3/14 (Alto=0/3;Moderado=1/3;Baixo=2/3))
- Renda anual: 14 é a quantidade de registros (<15000=3/14 (Alto=3/3;Moderado=0/3;Baixo=0/3)), (>=15000 e <35000=4/14 (Alto=2/4;Moderado=2/4;Baixo=0/4)), (>35000=7/14 (Alto=1/7;Moderado=1/7;Baixo=5/7))
- Entropia (História do crédito Boa): E(s) = -1/5 * log(1/5;2) -1/5 * log(1/5;2) -3/5 * log(3/5;2) = 1,37
- Entropia (História do crédito Desconhecida): E(s) = -2/5 * log(2/5;2) -1/5 * log(1/5;2) -2/5 * log(2/5;2) = 1,52
- Entropia (História do crédito Ruim): E(s) = -3/4 * log(3/4;2) -1/4 * log(1/4;2) -0/4 * log(0/4;2) = 0,81
- Entropia (Dívida Alta): E(s) = -4/7 * log(4/7;2) -1/7 * log(1/7;2) -2/7 * log(2/7;2) = 1,38
- Entropia (Dívida Baixa): E(s) = -2/7 * log(2/7;2) -2/7 * log(2/7;2) -3/7 * log(3/7;2) = 1,56
- Entropia (Garantias Nenhuma): E(s) = -6/11 * log(6/11;2) -2/11 * log(2/11;2) -3/11 * log(3/11;2) = 1,44
- Entropia (Garantias Adequada): E(s) = -0/3 * log(0/3;2) -1/3 * log(1/3;2) -2/3 * log(2/3;2) = 0,92
- Entropia (Renda anual <15000): E(s) = -3/3 * log(3/3;2) -0/3 * log(0/3;2) -0/3 * log(0/3;2) = 0,00
- Entropia (Renda anual >=15000 e <35000): E(s) = -2/4 * log(2/4;2) -2/4 * log(2/4;2) -0/4 * log(0/2;2) = 1,00
- Entropia (Renda anual >35000): E(s) = -1/7 * log(1/7;2) -1/7 * log(1/7;2) -5/7 * log(5/7;2) = 1,15
- Ganho (História do crédito): G = 1,53 - (5/14*1,37) - (5/14*1,52) - (4/14*0,81) = 0,26
- Ganho (Dívida): G = 1,53 - (7/14*1,38) - (7/14*1,56) = 0,06
- Ganho (Garantias): G = 1,53 - (11/14*1,44) - (3/14*0,92) = 0,20
- Ganho (Renda anual): G = 1,53 - (3/14*0,00) - (4/14*1,00) - (7/14*1,15) = 0,66
Ganho:
Conclusão (Prioridades):
-
Tal conclusão é mostrada visualmente na imagem acima, no ordenamento visual da Árvore de Decisão.
- Renda anual (0,66)
- História de crédito (0,26)
- Garantias (0,20)
- Dívida (0,06)
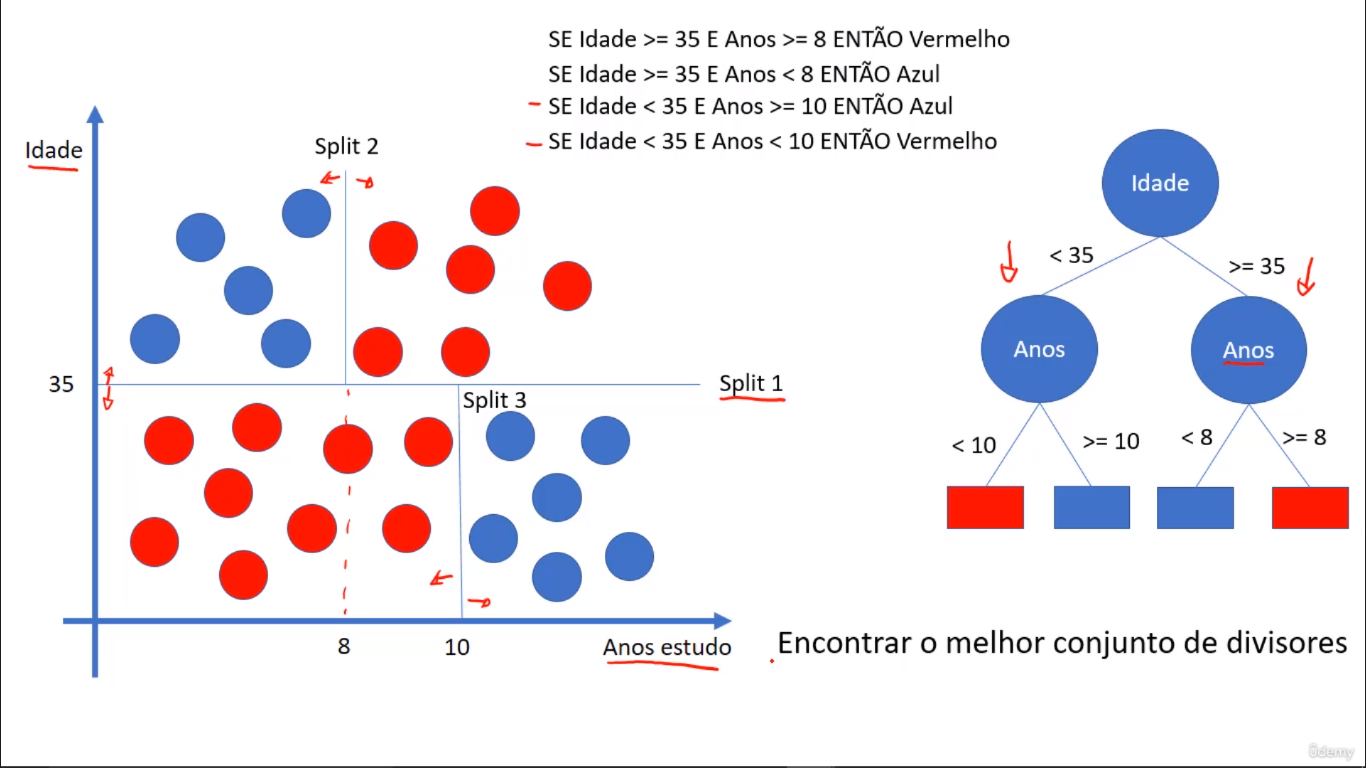
Representação alternativa:
Outra forma de geração de Árvore de Decisão é através da utilização de Splits (Divisão): Parâmetros ação da Árvore de Decisão, utilizados para dividir conjuntos de registros, a fim de identificar tipos de atributos dos mesmos. Posteriormente, tais Splits tornam-se regras (IF's).
Podas
Após a Árvore de Decisão estar completa, pode-se realizar podas em atributos da Árvore de Decisão com pouco ganho de informação. Raramente, em alguns casos, pode-se que, após a poda, o algoritmo da Árvore acabe errando em algumas situações, pois algumas informações foram removidas da mesma. Utiliza-se podas em cenários que encontram-se:
- Bias (Viés): Erros por classificação errada;
- Variância: Erros por sensibilidade pequena a mudanças na base de treinamento, onde haverão ramos muito específicos/amarrados à determinadas situações no último nível da Árvore. Pode levar a overfitting (Algoritmo se adapta excessivamente aos dados do treinamento, ficando amarrado aos mesmos, ou seja, decorar ao invés de aprender);
Base de Dados (Risco de Crédito - Pequena)
Aplicação de Árvore de Decisão para classificação de Risco de Crédito - Modelo teste.
#Importar libraries e upload do arquivo 'credit.pkl' com os dados e LabelEncoder aplicado:
from sklearn.tree import DecisionTreeClassifier
import pickle
with open('risco_credito.pkl', 'rb') as f:
X_risco_credito, y_risco_credito = pickle.load(f)
X_risco_credito
y_risco_credito
#Criar Árvore de Decisão e treiná-la:
arvore_risco_credito = DecisionTreeClassifier(criterion='entropy') #Por padrão, o criterion usa Gini (Cálculo de impureza de Gini), mas fora alterado para entropy (Cálculo da Entropia)
arvore_risco_credito.fit(X_risco_credito, y_risco_credito)
arvore_risco_credito.feature_importances_ #Ver valor do Ganho de Informação de cada atributo da Árvore
arvore_risco_credito.classes_ #Ver classes
#Visualizar Árvore de Decisão:
from sklearn import tree
tree.plot_tree(arvore_risco_credito) #Modo texto
previsores = ['história', 'dívida', 'garantias', 'renda']
figura, eixos = plt.subplots(nrows=1, ncols=1, figsize=(10,10))
tree.plot_tree(arvore_risco_credito, feature_names=previsores, class_names = arvore_risco_credito.classes_, filled=True);tree.plot_tree(arvore_risco_credito) #Modo gráfico (Imagem abaixo)
#Testar previsao com valores para teste:
#1. história boa, dívida alta, garantias nenhuma, renda > 35
#2. história ruim, dívida alta, garantias adequada, renda < 15
previsoes = arvore_risco_credito.predict([[0,0,1,2],[2,0,0,0]])
previsoes #Retornará, respectivamente, Baixo e Alto
Base de Dados (Risco de Crédito - credit data)
Aplicação de Árvore de Decisão para classificação de Risco de Crédito.
#Upload do arquivo 'credit.pkl' do credit data com dados e padronização aplicada:
with open('credit.pkl', 'rb') as f:
X_credit_treinamento, y_credit_treinamento, X_credit_teste, y_credit_teste = pickle.load(f)
#Visualizar números de quantidades (Registros, colunas):
X_credit_treinamento.shape, y_credit_treinamento.shape
X_credit_teste.shape, y_credit_teste.shape
#Criar Árvore de Decisão e treiná-la:
arvore_credit = DecisionTreeClassifier(criterion='entropy', random_state = 0) #Random State 0 o algoritmo sempre executará no mesmo ordenamento, facilitando comparações
arvore_credit.fit(X_credit_treinamento, y_credit_treinamento)
#Testar previsao com base para teste:
previsoes = arvore_credit.predict(X_credit_teste)
previsoes #0 indica pagador, 1 indica não pagador
y_credit_teste #Comparar previsões com respostas reais:
#Visualizar métricas de comparação:
from sklearn.metrics import accuracy_score, classification_report
accuracy_score(y_credit_teste, previsoes) #Precisão de 0,982 (98,2%)
#Gerar matriz de confusão (Eixo y (Vertical) é a resposta real, eixo x (Horizontal) é a resposta de previsão):
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(arvore_credit)
cm.fit(X_credit_treinamento, y_credit_treinamento)
cm.score(X_credit_teste, y_credit_teste)
#Gerar classification_report:
print(classification_report(y_credit_teste, previsoes)) #Recall: O algoritmo consegue identificar x% corretamente. Precision: Quando o algoritmo acerta a previsão, o mesmo está correto em x% dos casos.
#Visualizar Árvore de Decisão:
arvore_credit.classes_ #Classes, que serão convertidas em String para a visuazação na Árvore abaixo
from sklearn import tree
previsores = ['income', 'age', 'loan']
fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (20,20))
tree.plot_tree(arvore_credit, feature_names=previsores, class_names=['0','1'], filled=True);
fig.savefig('arvore_credit.png') #Salvar imagem da Árvore em arquivo
Base de Dados (Censo)
Aplicação de Árvore de Decisão para classificação de valor salarial.
#Upload do arquivo 'census.pkl' do credit data com dados e OneHotEncoder aplicado:
with open('census.pkl', 'rb') as f:
X_census_treinamento, y_census_treinamento, X_census_teste, y_census_teste = pickle.load(f)
#Visualizar números de quantidades (Registros, colunas):
X_census_treinamento.shape, y_census_treinamento.shape
X_census_teste.shape, y_census_teste.shape
#Criar Árvore de Decisão e treiná-la:
arvore_census = DecisionTreeClassifier(criterion='entropy', random_state=0)
arvore_census.fit(X_census_treinamento, y_census_treinamento)
previsoes = arvore_census.predict(X_census_teste)
previsoes
y_census_teste #Comparar previsões com respostas reais:
#Visualizar métricas de comparação:
accuracy_score(y_census_teste, previsoes) #Precisão de 0,810 (81%)
#Gerar matriz de confusão:
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(arvore_census)
cm.fit(X_census_treinamento, y_census_treinamento)
cm.score(X_census_teste, y_census_teste)
#Gerar classification_report:
print(classification_report(y_census_teste, previsoes))
Random Forest:
São melhorias no processo de Árvore de Decisão, para adquirir melhor desempenho. Neste processo, utilizam-se várias Árvores de Decisão (Ensemble learning), escolhendo aleatoriamente K atributos para comparação da métrica pureza/impureza (impureza de gini/entropia), combinando cada conclusão final de Árvore de acordo com a média (Regressão) ou votos da maioria (Classificação) a fim de chegar em conclusão geral final. A quantidade de K atributos pode ser escolhida manualmente ou automaticamente (Algoritmo faz raíz quadrada do total de atributos da base). Supondo que hajam 3 Árvores para calcular Risco de Crédito e 3 atributos (K=3) diferentes entre si: a 1ª conclui 'Alto', a 2ª 'Baixo' e a 3ª 'Baixo'. Então, prevalece a conclusão 'Baixo'. Entretanto, quanto mais Árvores haverem no algoritmo, mais provável sera a chance de overfitting.
Base de Dados (Risco de Crédito - credit data)
Aplicação de Árvore de Decisão, com Random Forest, para classificação de Risco de Crédito.
#Importar libraries:
from sklearn.ensemble import RandomForestClassifier
import pickle
#Upload do arquivo 'credit.pkl' do credit data com dados e padronização aplicada:
with open('credit.pkl', 'rb') as f:
X_credit_treinamento, y_credit_treinamento, X_credit_teste, y_credit_teste = pickle.load(f)
#Visualizar números de quantidades (Registros, colunas):
X_credit_treinamento.shape, y_credit_treinamento.shape
X_credit_teste.shape, y_credit_teste.shape
#Criar treinamento Random Forest (40 Árvores), gerar previsões:
random_forest_credit = RandomForestClassifier(n_estimators=40, criterion='entropy', random_state = 0)
random_forest_credit.fit(X_credit_treinamento, y_credit_treinamento)
previsoes = random_forest_credit.predict(X_credit_teste)
previsoes
y_credit_teste #Comparar 'previsoes' com respostas reais (0 paga, 1 não paga empréstimo)
#Visualizar métricas de comparação:
from sklearn.metrics import accuracy_score, classification_report
accuracy_score(y_credit_teste, previsoes) #Precisão de 0,984 (98,4%)
#Gerar matriz de confusão:
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(random_forest_credit)
cm.fit(X_credit_treinamento, y_credit_treinamento)
cm.score(X_credit_teste, y_credit_teste)
#Gerar classification_report:
print(classification_report(y_credit_teste, previsoes)) #O algoritmo consegue identificar corretamente 99% dos elementos da classe 0 (Recall). Quando identifica, 99% das vezes está correto (Precision)
Base de Dados (Censo)
Aplicação de Árvore de Decisão, com Random Forest, para classificação de valor salarial.
#Importar libraries:
from sklearn.ensemble import RandomForestClassifier
import pickle
#Upload do arquivo 'census.pkl' do credit data com dados e OneHotEncoder aplicado:
with open('census.pkl', 'rb') as f:
X_census_treinamento, y_census_treinamento, X_census_teste, y_census_teste = pickle.load(f)
#Visualizar números de quantidades (Registros, colunas):
X_census_treinamento.shape, y_census_treinamento.shape
X_census_teste.shape, y_census_teste.shape
y_census_treinamento #Ver classes
#Criar treinamento Random Forest (100 Árvores - padrão), gerar previsões:
random_forest_census = RandomForestClassifier(n_estimators=100, criterion='entropy', random_state = 0)
random_forest_census.fit(X_census_treinamento, y_census_treinamento)
previsoes = random_forest_census.predict(X_census_teste)
previsoes
y_census_teste #Comparar 'previsoes' com respostas reais
Verificar accuracy:
from sklearn.metrics import accuracy_score, classification_report
accuracy_score(y_census_teste, previsoes) #0.8507676560900717 (85%)
#Gerar matriz de confusão:
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(random_forest_census)
cm.fit(X_census_treinamento, y_census_treinamento)
cm.score(X_census_teste, y_census_teste)
#Gerar classification_report:
print(classification_report(y_census_teste, previsoes))
----- Aprendizagem por Regras -----
Geração de regras (IF..THEN) e, após isso, novos registros serão submetido às mesmas (Todos atributos envolvidos True, então usa-se tal regra e tem-se a previsão). No geral, algoritmos de regras tendem a serem mais lentos do que de Árvores, não havendo diferença de melhores resultados de previsões quando ambos comparados. Utilizou-se, como exemplo, os dados da base de risco de crédito (Aqui).
- Se renda =>35000 E história de crédito = boa, ENTÃO risco = baixo
- Se renda =>35000 E história de crédito = desconhecida, ENTÃO risco = baixo
- Default (Padrão), ENTÃO risco = alto
OneR
OneRules, gerará 1 regra baseada em 1 atributo mais importante. Submetendo tal algoritmo na base Risco de Crédito, gerará a seguinte tabela, onde o atributo 'Renda' foi escolhido como principal, pois há menor chance de erro (Total erro). Esse mesmo algoritmo pode ser testado no software Weka.
| Atributo | Quantidade | Regras | Erro | Total erro |
|---|---|---|---|---|
| História de Crédito | Boa 5 | SE boa ENTÃO baixo | 2/5 | 6/14 |
| Desconhecida 5 | SE desconhecida ENTÃO alto | 3/5 | ||
| Ruim 4 | SE ruim ENTÃO alto | 1/4 | ||
| Dívida | Alta 7 | SE alta ENTÃO alto | 3/7 | 7/14 |
| Baixa 7 | SE baixa ENTÃO baixo | 4/7 | ||
| Garantias | Nenhuma 11 | SE nenhuma ENTÃO alto | 5/11 | 6/14 |
| Adequada 3 | SE adequada ENTÃO baixo | 1/3 | ||
| Renda | <15000 3 | SE <15000 ENTÃO alto | 0 | 4/14 |
| >=15000 a <=35000 4 | SE >=15000 a <=35000 ENTÃO alto | 2/4 | ||
| >35000 7 | SE >35000 ENTÃO baixo | 2/7 |
Para a montagem das regras acima, contabilizam-se as possibilidades de cada regra/atributo. O exemplo abaixo fora utilizado somente 'História de Crédito' (Deve ser feito com todos), pois para as demais segue a mesma lógica:
-
História de Crédito:
- SE boa ENTÃO alto (1)
- SE boa ENTÃO moderado (1)
- SE boa ENTÃO baixo (3) - Escolhida
- ERRO: Para cada 5 (Total), 2 podem ser errados (2 fora da regra escolhida) = 2/5
- SE desconhecida ENTÃO alto (2) - Escolhida (Não há critério em empates, aparece primeiro)
- ERRO: Para cada 5, 3 podem ser errados = 3/5
- SE desconhecida ENTÃO moderado (1)
- SE desconhecida ENTÃO baixo (2)
- SE ruim ENTÃO alto (3) - Escolhida
- ERRO: Para cada 4, 1 pode ser errado = 1/4
- SE ruim ENTÃO moderado (1)
- SE ruim ENTÃO baixo (0)
- TOTAL ERRO: (2+3+1)/(5+5+4) = 6/14
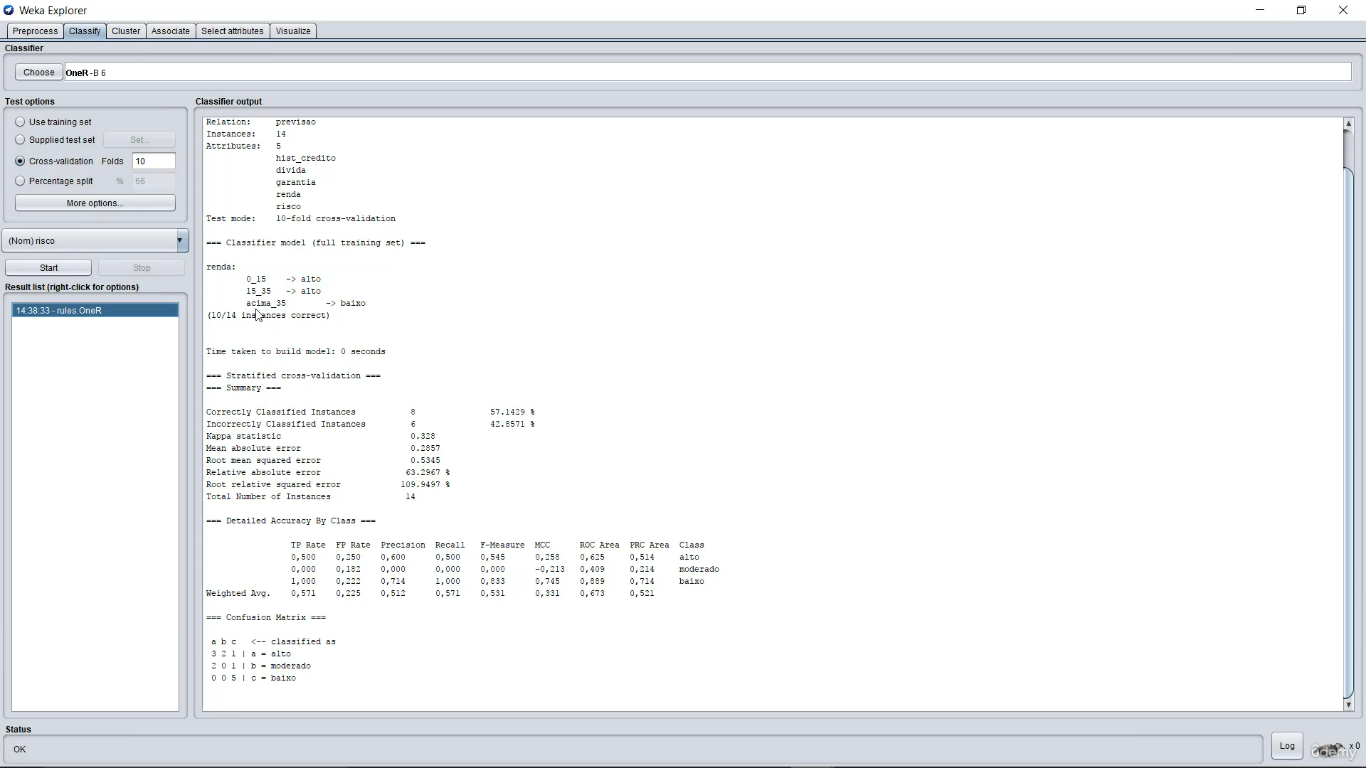
*Weka (Arquivo risco_credito.arff submetido ao OneR)
PRISM
Gerar 1 regra específica com vários atributos, identificando-os via maior abrangência, que classificará os registros conforme resposta esperada. Exemplo, passo a passo, da montagem da regra:
- SE ? ENTÃO risco = alto
- SE garantias = nenhuma ENTÃO risco = alto
| Atributo/Valor | Abrangência |
|---|---|
| História de crédito = Boa | 1/1 (História de crédito boa E risco alto) |
| História de crédito = Desconhecida | 2/2 |
| História de crédito = Ruim | 3/3 |
| Dívida = Alta | 4/4 |
| Dívida = Baixa | 2/2 |
| Garantias = Nenhuma (Mais abrangente) | 6/6 |
| Garantias = Adequada | 0/3 (3 Garantias adequadas, mas nenhuma com risco alto) |
| Renda = <15000 | 3/3 |
| Renda = 15000-35000 | 2/2 |
| Renda = >35000 | 1/1 |
- SE garantias = nenhuma E ? ENTÃO risco = alto
- SE garantias = nenhuma E dívida = alta ENTÃO risco = alto
| Atributo/Valor | Abrangência |
|---|---|
| História de crédito = Boa | 1/1 (História de crédito boa E garantias nenhuma E risco alto) |
| História de crédito = Desconhecida | 2/2 |
| História de crédito = Ruim | 3/3 |
| Dívida = Alta (Mais abrangente) | 4/4 |
| Dívida = Baixa | 2/2 |
| Renda = <15000 | 3/3 |
| Renda = 15000-35000 | 2/2 |
| Renda = >35000 | 1/1 |
- SE garantias = nenhuma E dívida = alta E ? ENTÃO risco = alto
- SE garantias = nenhuma E dívida = alta E história = ruim ENTÃO risco = alto
| Atributo/Valor | Abrangência |
|---|---|
| História de crédito = Boa | 1/1 (História de crédito boa E garantias nenhuma E dívida alta E risco alto) |
| História de crédito = Desconhecida | 1/1 |
| História de crédito = Ruim (Mais abrangente) | 2/2 |
| Renda = <15000 | 2/2 |
| Renda = 15000-35000 | 2/2 |
| Renda = >35000 | 0 |
- SE garantias = nenhuma E dívida = alta E história = ruim E ? ENTÃO risco = alto
- SE garantias = nenhuma E dívida = alta E história = ruim E renda <15000 ENTÃO risco = alto
| Atributo/Valor | Abrangência |
|---|---|
| Renda = <15000 (Mais abrangente) | 1/1 |
| Renda = 15000-35000 | 1/1 |
| Renda = >35000 | 0 |
- Após isso, o mesmo deverá ser feito para 'risco = médio' e 'risco = baixo'
OBSERVAÇÃO: Como os registros acima foram bastante específicos (Ex: 1/1), pode-se ocorrer overfitting! Para evitar isso, pode-se utilizar 'poda' de tais atributos muito específicos, ou seja, com poucos dados envolvidos.
Base de Dados (Risco de Crédito - Pequena)
Aplicação de Indução de Regras para classificação de Risco de Crédito - Modelo teste.
#Importar libraries e upload do arquivo com dados, LabelEncoder aplicado e organizado para Orange, com 'c#risco' para atributo classe:
!pip install Orange3
import Orange
base_risco_credito = Orange.data.Table('risco_credito_regras.csv')
base_risco_credito
base_risco_credito.domain #Mostrar cabeçalho/domínio
#(Treinamento) Criar regras, submetendo os dados ao algoritmo de regras 'cn2':
cn2 = Orange.classification.rules.CN2Learner()
regras_risco_credito = cn2(base_risco_credito)
for regras in regras_risco_credito.rule_list:
print(regras)
#Testar previsão com valores para teste:
previsoes = regras_risco_credito([['boa', 'alta', 'nenhuma', 'acima_35'], ['ruim', 'alta', 'adequada', '0_15']])
previsoes #Obteve-se 1 e 0
base_risco_credito.domain.class_var.values #0 é alto, 1 é baixo, 2 é moderado
for i in previsoes:
#print(i)
print(base_risco_credito.domain.class_var.values[i])
Base de Dados (Risco de Crédito - credit data)
Aplicação de Indução de Regras para classificação de Risco de Crédito.
#Importar libraries e upload do arquivo com dados e padronização aplicada, com 'i#clientid' para ser ignorado, e 'c#default' para atributo classe:
!pip install Orange3
import Orange
base_credit.domain #Mostrar cabeçalho/domínio
Dividir base de dados treinamento-teste:
base_dividida = Orange.evaluation.testing.sample(base_credit, n = 0.25) #25% para teste, 75% para treino
base_dividida
base_dividida[0]
base_dividida[1]
base_teste = base_dividida[0]
base_treinamento = base_dividida[1]
len(base_teste), len(base_treinamento)
#(Treinamento) Criar regras, submetendo os dados ao algoritmo de regras 'cn2':
cn2 = Orange.classification.rules.CN2Learner()
regras_credit = cn2(base_treinamento)
for regras in regras_credit.rule_list:
print(regras)
#Testar previsão com valores para teste:
previsoes = Orange.evaluation.testing.TestOnTestData(base_treinamento, base_teste, [lambda testdata: regras_credit])
Orange.evaluation.CA(previsoes) #(97,4%) CA para 'Classification Accuracy', ou F1 para 'F1 Score'
Base de Dados (Censo) - Orange GUI
Aplicação de Indução de Regras, via Orange GUI, para classificação de valor salarial. Instalar Orange via 'pip3 install orange3'.
Seguindo o passo a passo da modelagem, tem-se 80,7% de accuracy.
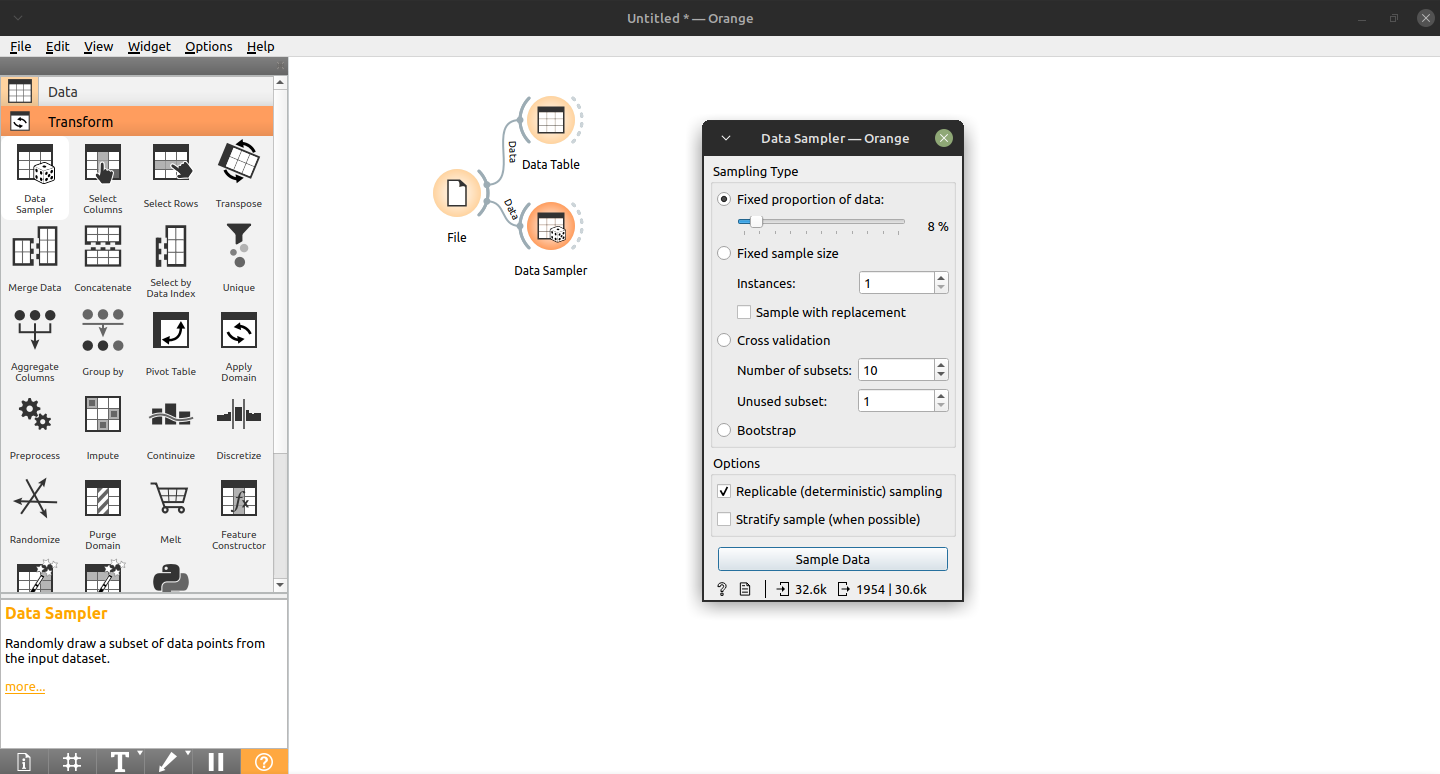
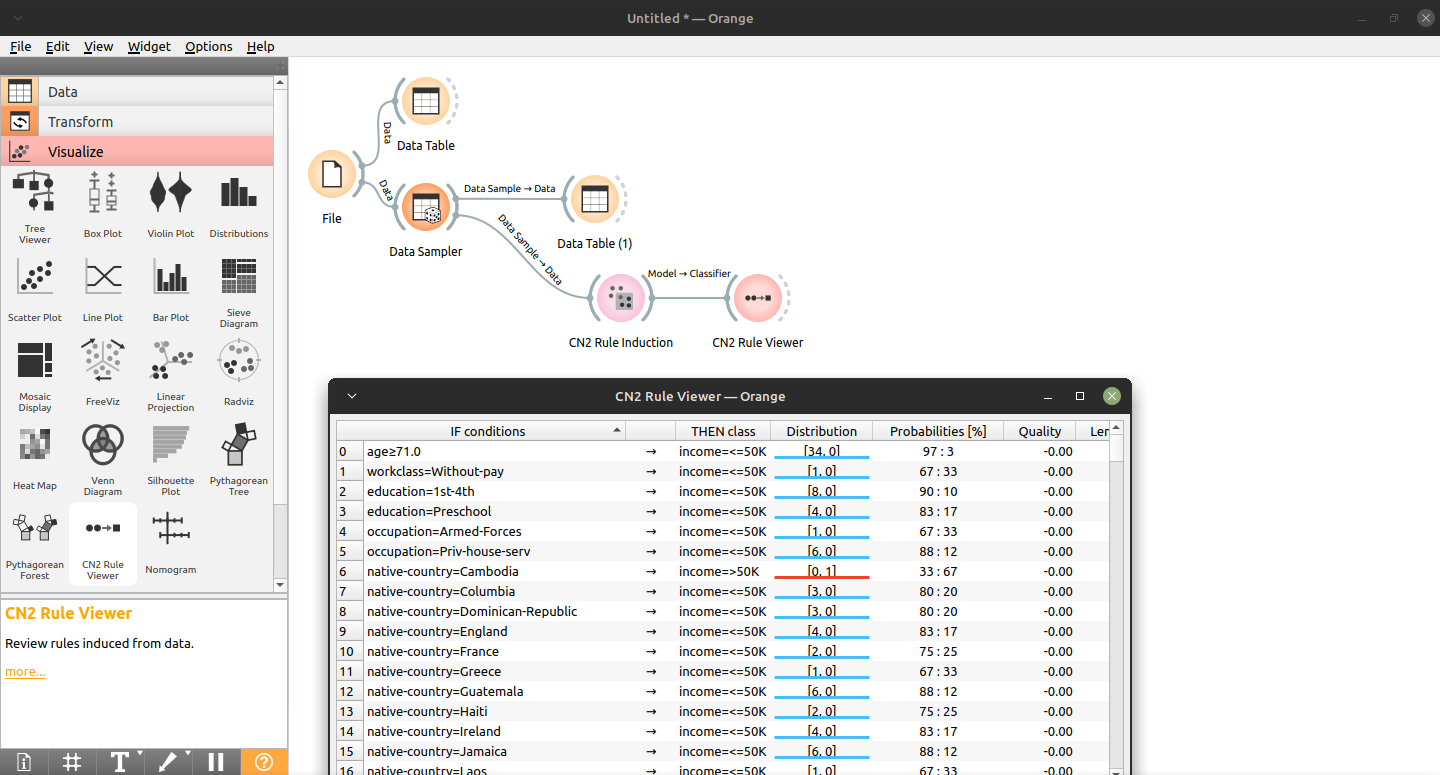
Base de Dados (Risco de Crédito - credit data)
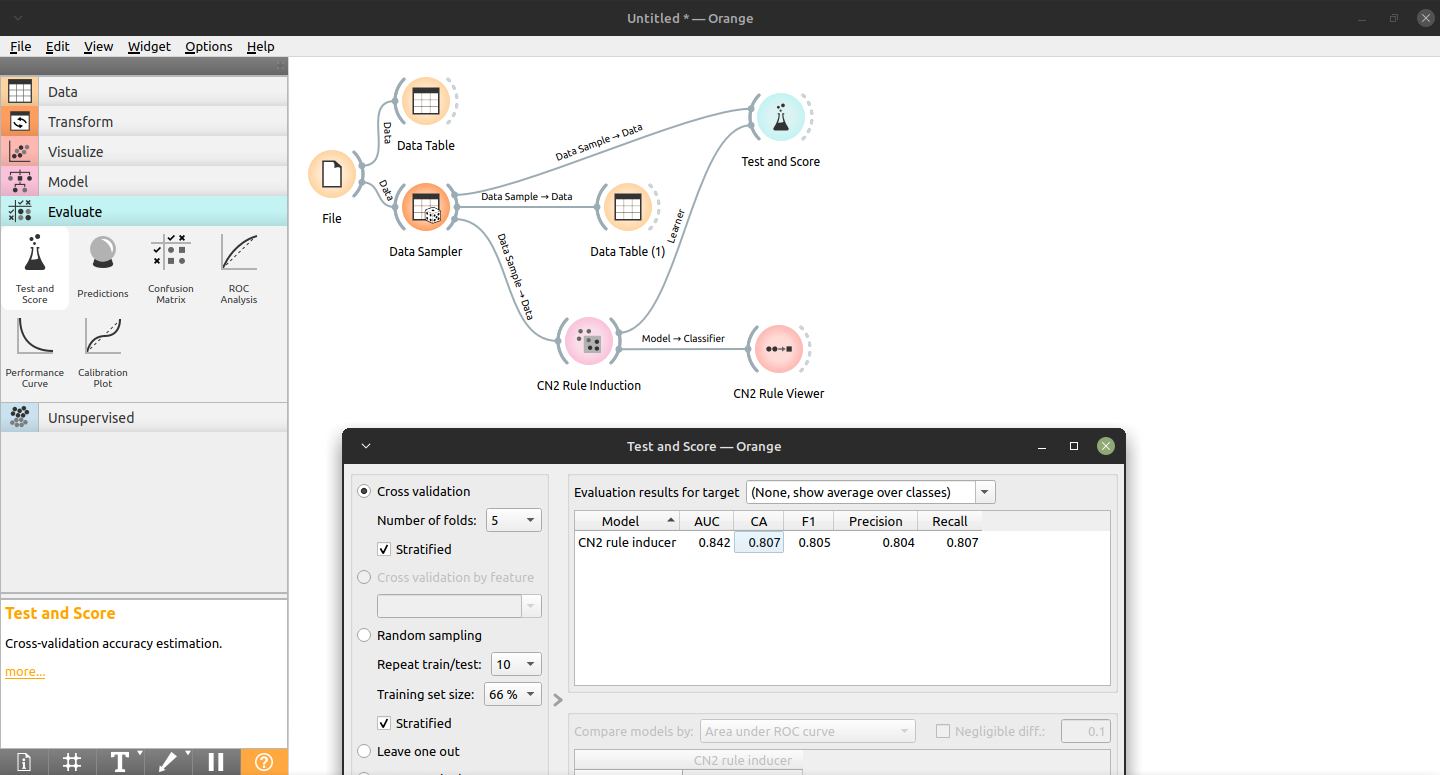
Aplicação de Indução de Regras, via Orange GUI, para classificação de Risco de Crédito.
Seguindo o passo a passo da modelagem, tem-se 96,2% de accuracy.
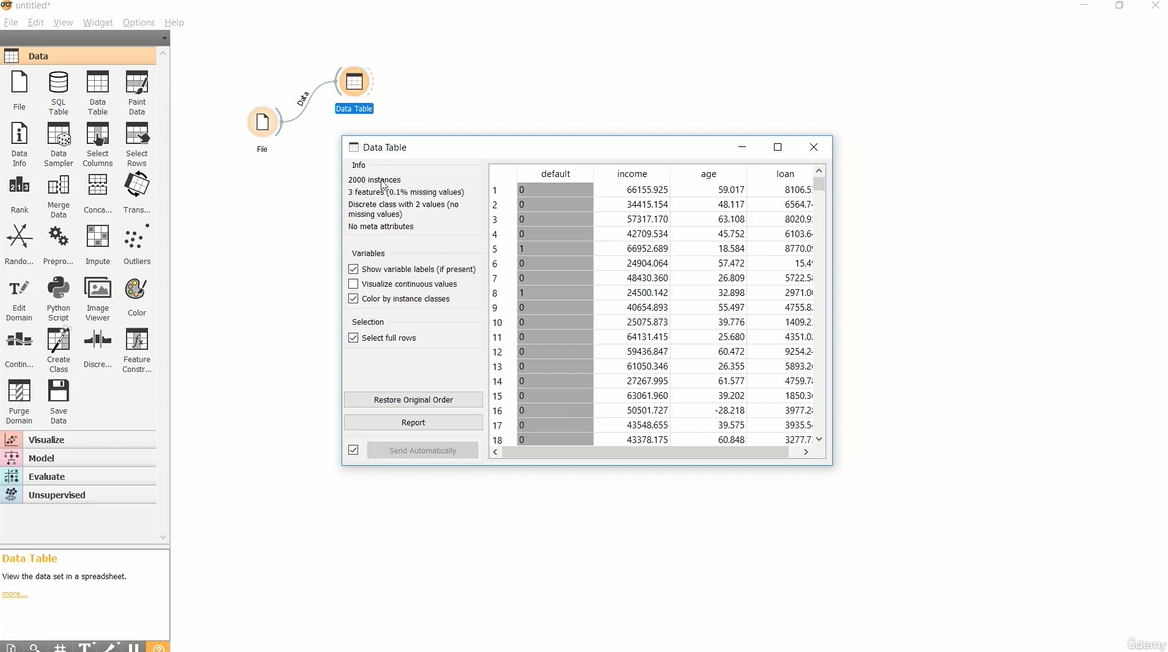
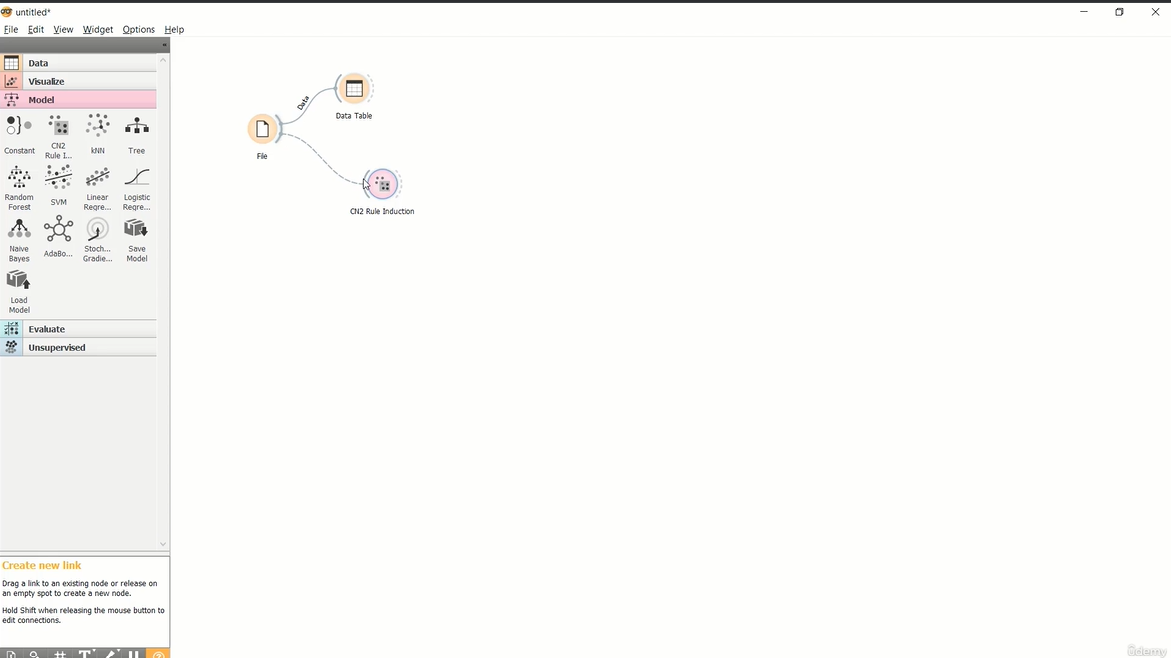
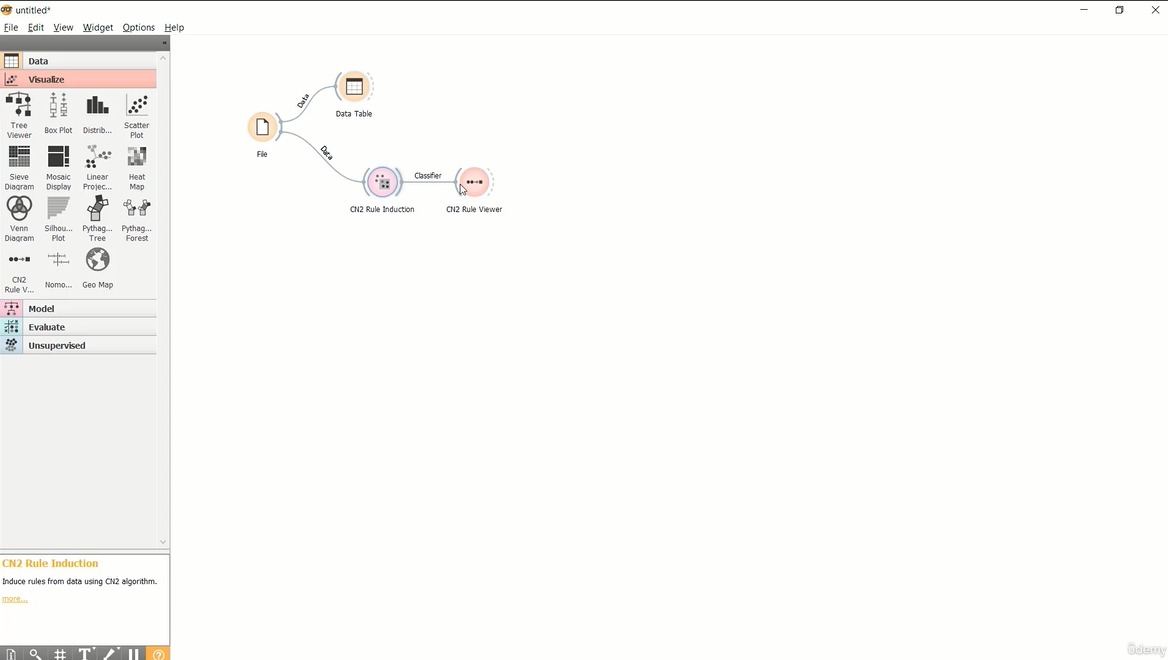
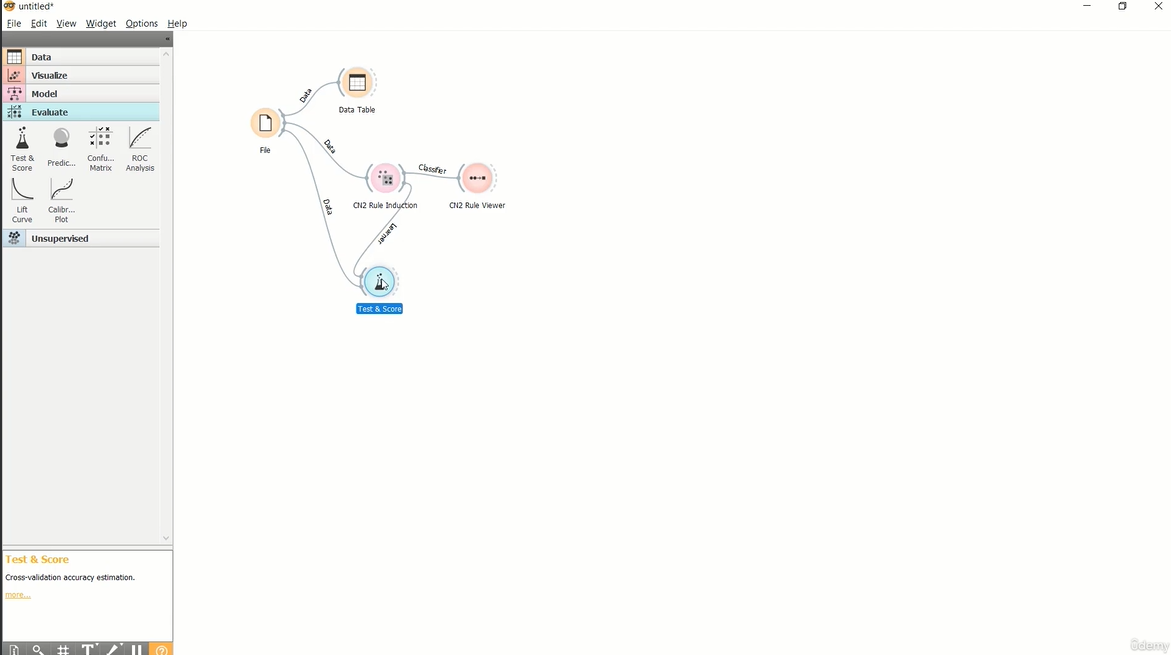
----- Majority learner (ZeroR) -----
Classificar dados conforme histórico de treino. Exemplo, maioria dos clientes do banco x pagam empréstimo, então novo cliente do banco x será classificado como pagador. Algoritmo muito utilizado para avaliar outros algoritmos ML.
Base de Dados (Risco de Crédito - credit data)
base_credit = Orange.data.Table('credit_data_regras.csv') #via biblioteca orange
base_credit.domain
majority = Orange.classification.MajorityLearner() #criar algoritmo ML
previsoes = Orange.evaluation.testing.TestOnTestData(base_credit, base_credit, [majority]) #treinar e testar mesma base_credit, via majority (dispensará treinamento)
Orange.evaluation.CA(previsoes) #avaliação de aprox 86%
for registro in base_credit: #valores da classe
print(registro.get_class())
from collections import Counter
Counter(str(registro.get_class()) for registro in base_credit) #contagem de tipos de valores da classe (valContagemMaioria/valTotal=evaluationModelo)
#Nesse dataset, se algoritmo ML acertar menos que 85%, deve ser descartado. Do contrário, pode ser mantido
Base de Dados (Censo)
base_census = Orange.data.Table('census_regras.csv')
base_census.domain
majority = Orange.classification.MajorityLearner()
previsoes = Orange.evaluation.testing.TestOnTestData(base_census, base_census, [majority])
Orange.evaluation.CA(previsoes) #avaliação de aprox 76%
Counter(str(registro.get_class()) for registro in base_census)
----- KNN (k-nearest neighbors) -----
Algoritmo de aprendizagem baseada em instâncias (k-ésimo vizinho mais próximo). Classificará dado x conforme outro dado y já classificado no dataset, que possui previsores de valores mais próximos aos do dado x, via menor valor de cálculo de distância euclidiana. Parâmetro k indica quantidade de vizinhos mais próximos para determinar classificação no algoritmo. Se dado x, com k=2, onde os vizinhos mais próximos são diferentes, então há possibilidade de x ser um dos dois (empate, pode ser resolvido escolhendo vizinho mais próximo). Se dado x, em k=3, onde vizinhos 2 e 3 são iguais, então x será como 2 e 3, pois há mais vizinhos próximos com essa classificação. Valor k muito elevado, tende a diminuir a accuracy de classificação. Algoritmo KNN não constrói modelo para classificar (lazy), somente realiza cálculo de distância euclidiana. Quanto menor a distância euclidiana, maior a proximidade (similaridade) entre elementos. KNN é usado em sistemas de recomendações, como filtragem colaborativa.
Distância euclidiana calcula proximidade entre vetores, como x e y.
- Exemplo x=5,7,9 e y=5,5,5 onde p é valor inicial, ou seja, quantidade de registros (3 registros) e i é valor final, posição (xi é valor na mesma posição que yi).
- Subtração dos valores (5-5=0 e 7-5=2 e 9-5=4)
- Elevação ao quadrado (0²=0 e 2²=4 e 4²=16)
- Somatório (0+4+16=20)
- Raíz quadrada (raíz(20)=4,47) é a distância euclidiana
Elaborado por Mateus Schwede
ubsocial.github.io