Plataforma de streaming de eventos, que recebe (push), organiza (topics in brokers) e envia (pull) dados (messages). Ex: Sistema de folha de pagamentos possui BD compartilhado com vários setores da empresa. Tal sistema produz dados, demais setores os consomem. Tecnicamente, é software EDA (event driven architecture - arquitetura orientada a eventos), atuando com event streaming (captura, análise e resposta a events, em real-time, via TCP). Praticamente, Kafka auxiliará no processo de produção/consumo dos dados, evitando sobrecargas no BD, indisponibilidades e falhas, baixo desempenho, etc.
Estrutura:
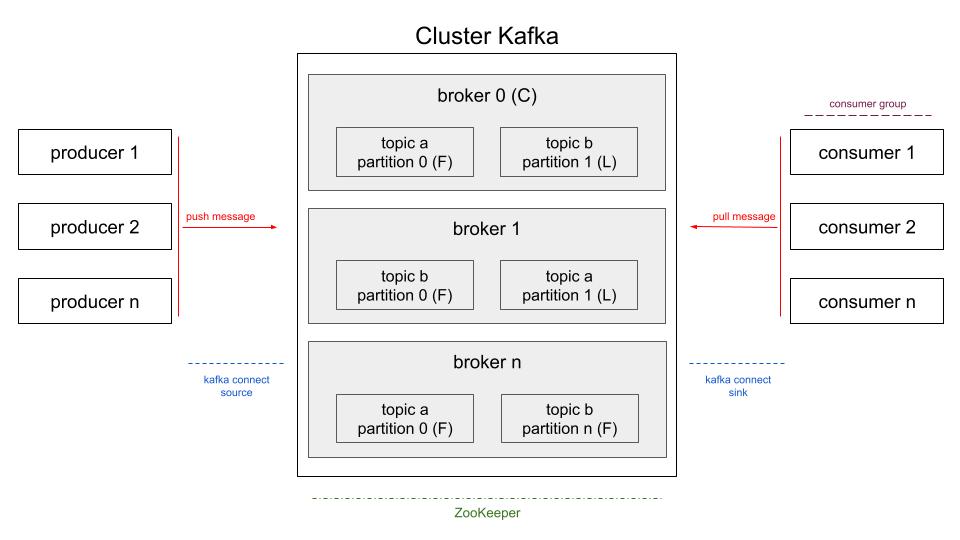
producer -(push message)-> Cluster Kafka (topic in broker) <-(pull message)- consumer
- Producer/publisher: Produtor das messages (dados), que a enviará para um topic (assunto - tabela de armazenamento), em um broker (servidor) no Kafka;
- Consumer/subscriber: Consumidor das messages, pode lê-las mais de uma vez.
Event:
Mudança significativa dos dados (possui chave, valor e data). Exemplo: comando de 'update' em table. No Kafka, events são messages. Componentes básicos de um event:
- Event key: "fulana"
- Event value: "café no starbucks"
- Event timestamp: "Jun. 23, 2024 at 8:00 p.m."
Broker:
Servidor lógico do Kafka, faz intermédio producer-consumer. Cada node físico executa 1 ou mais brokers. Pode-se acessar, num mesmo broker, diferentes instâncias na mesma porta. Atribui numeração ordenada (offset) às messages. Broker chefe é escolhido aleatoriamente e denominado controller. Bootstrap é a porta lógica de entrada para conexão em topic (em broker qualquer), para producer e consumer.
Cluster Kafka:
Cada servidor físico é um broker. Cada broker pode ter 0 ou mais topics. Cada topic pode ter várias partitions (partições físicas), distribuídas em diferentes brokers. Cada topic pode ter somente 1 partition num mesmo broker. Podem haver brokers que não possuam partitions de determinados topics. Num mesmo broker, não pode haver mesmo topic duplicado. Num mesmo broker, pode haver mesma partition armazenando diferentes topics. Partitions são armazenadas, fisicamente, em node único do cluster, mas podendo estar, logicamente, replicada em diferentes brokers.
Controller:
Broker principal do cluster (se controller cair, outro broker assumirá). Cada broker possui topics em partitions. Partitions principais são denominadas leaders, e suas cópias são denominadas followers. Cada partition é replicada em 1 leader e 1 ou mais followers, distribuídas em diferentes brokers (quantidade de followers depende do fator de replicação). Cada broker possui 0 ou mais partitions leaders e 0 ou mais followers. Pode haver broker somente com leaders, somente com followers, ou com ambas. Um broker possui pelo menos 1 partition. Recomendável que followers estejam em brokers separados de suas leaders (mesma partition compartilhada, via replicação, em diferentes brokers) e, com isso, em diferentes servidores e racks (tolerância a falhas). Partition leader guarda requisições dos producers e consumers. Producer recebe lista (ISR) de leaders e decide para qual delas enviar (push) as messages. Producer enviará message para broker da partition leader escolhida, que a guardará enviará feedback (acknowledgement). Consumer consome (pull) messages da partition leader.
Exemplo de replicação: 3 brokers em diferentes racks, 1 topic em 4 partitions com 3 réplicas (1 leader e 2 followers), totalizando 12 partitions:
- Ordenar brokers (broker 0, broker 1, broker 2);
- (réplica 1) Distribuir partitions leaderes entre os brokers;
- broker 0 recebe partition leader 0;
- broker 1 recebe partition leader 1;
- broker 2 recebe partition leader 2;
- broker 0 recebe partition leader 3;
- (réplica 2) Distribuir 1ª partition follower entre os brokers;
- broker 1 recebe partition follower 0;
- broker 2 recebe partition follower 1;
- broker 0 recebe partition follower 2;
- broker 1 recebe partition follower 3;
- (réplica 3) Distribuir 2ª partition follower entre os brokers;
- broker 2 recebe partition follower 0;
- broker 0 recebe partition follower 1;
- broker 1 recebe partition follower 2;
- broker 2 recebe partition follower 3.
Obs: Caso algum broker estivesse no mesmo rack de outro, o Kafka não repetiria as mesmas partitions entre esses.
Partitions followers não respondem requisições (mantém-se atualizadas via leader). Followers existem somente para backup. Objetivo da follower é ser leader, em caso de falhas (follower somente será leader se estiver atualizada). Conforme exemplo acima, se no broker 1 a partition leader 1 falhar, sua partition follower 1 (no broker 2) se tornará leader no broker 2. Então, broker 1 possuirá somente followers a partir desse momento, e broker 2 possuirá 2 leaders.
ISR (in-sync-replicas):
Lista, mantida pelo broker com a leader, de followers que estão em sincronia com suas leaderes. Quando partition leader falha, Kafka verifica quais followers a essa estão na lista, para tornar uma delas leader. A lista mantém-se atualizada via offsets solicitados pelas followers (se follower solicitou messages atualizadas nos últimos 10seg, tal follower se mantém na lista).
Se leader falhar, e todas suas followers estiverem fora da ISR? Pode-se configurar leader para não considerar messages confirmadas até que sejam copiadas em todas suas followers da ISR. Então, leader pode ter messages confirmadas e não confirmadas. Se leader falhar, perdem-se somente messages não confirmadas, que precisam ser reenviadas pelo producer, o qual fica aguardando feedback de recebimento (acknowledgement).
Minimum ISR list: Lista com nº mínimo de réplicas definidas. Se houver problema, broker não aceitará messages, pois não há followers suficientes. Leader torna-se read only, onde não poderá mais receber novas messages.
Arquivos segments: Messages ficam em arquivos, em diretórios denominados 'logs'. Arquivos de partitions são divididos em arquivos menores, os segments. Tudo numa mesma partition, dados vão do 1º segmento, até o limite, então inicia novo arquivo. Por padrão, tamanho máximo de segmento é 1GB ou 7 dias (configurável). Offset não é nº único no topic (não reinicia em novo segment), mas sim na partition (partition será dividida em novo segment, mas offset continua sua sequência. Cada partition tem seu próprio offset, independente da quantidade de segments). Partition offset permite manter o state, também reiniciá-lo, além de identificar menssages de forma única.
Arquivos timeindex: Arquivo nas messages em 'log', permite buscar messages em intervalo de tempo (ex: messages enviadas pelos producers entre minutos x e y).
ZooKeeper:
Realiza gestão física do cluster (máquina/node master gerencia demais nodes workers/slaves). Futuramente, ZooKeeper será substituído por 'real-time' KRaft no Kafka 4. Pode-se ter 1 ou mais ZooKeepers gerenciando um ou mais brokers (com ZooKeeper, será 1 broker leader, e 0 ou mais followers).
Topic:
Assunto, imutável, semelhante à tabela de BD, para armazenar messages. Ex: topics para gerenciar logs de websites. Cada producer (websites) enviam messages (error, warning, success) para respectivos topics, que serão consumidas pelos consumers da equipe de TI (dev, segurança, marketing). Cada message possui key (chave, similar ao header request). Além disso, cada message possui período de retenção (determinado por tamanho ou tempo) e pode reter apenas última message (log compacted). Messages são distribuídas nas partitions. As partitions não precisam ter mesma quantidade de topics, e partitions não podem ser divididas posteriormente, e só pode haver 1 consumer por partition. Offsets são commitados em mesmo topic, denominado '__consumer_offsets', onde o commit é o ponto de referência para o offset procurado para ser lido. Messages são identificadas por topic, seguido do nº da partition e, então, offset. Messages podem ser serializadas para transferência em rede, no formato Avro.
Escopo de message:
- Argumentos obrigatórios:
- Topic
- Mensagem
- Opcionais:
- Partition
- Conforme estratégia de particionamento
- Default: hash key ou rodízio
- Timestamp (hora da criação ou hora do log)
- Message key: usado para particionamento, agrupamento, joins, etc
Producer:
A qualquer momento pode-se adicionar e remover producers e consumers, sem afetar a plataforma. A partition de envio da message pode ser definida no objeto ProducerRecord, da API do Kafka. A message pode ter uma key, como referência da partition onde ficará. Caso contrário, ocorre rodízio. A lógica de particionamento pode ser definida pelo usuário. Pode-se criar producers e consumers via console, API Kafka ou Kafka Connect. Tipos de producer:
- Single thread: Para poucas messages;
- Multi thread: Escala o producer. Multi thread save permite compartilhar mesmo thread e usar mesmo producer para enviar messages em paralelo (mais recomendável do que criar múltiplos producers).
Consumer:
Lê messages, ordenadamente, de uma partition de um broker. Um consumer pode ler messages de mais de uma partition. Não há garantia de ordem entre partitions num mesmo topic, apenas dentro de cada partition. O consumer group dividirá processamento para determinado topic. Consumer groups geralmente são criados quando alguns consumers não conseguem processar todas as messages. A quantidade de partitions em determinado topic é a quantidade limite de consumers em um consumer group, que processará tais messages (os demais consumers no group ficarão inativos). Dentro de mesmo group, cada consumer lê sua(s) partition(s) específica(s) (um consumer pode ler mais de uma partition, se essas não estão sendo lidas por outros consumers do mesmo group). Portanto, de forma geral, não pode-se ter mais consumers do que partitions. Para ter mais de 1 consumer lendo mesma partition, deve-se criar novo group.
Acknowledgment:
Producer pode, ou não, aguardar confirmação de recebimento da message, via parâmetros acks:
- 0: Producer sempre considera message enviada com sucesso;
- 1: Producer considera message enviada com sucesso, se confirmada pela partition leader;
- All: Producer considera message enviada com sucesso, se todas réplicas mínimas sincronizadas receberem a message.
Transactions:
Similar a BDs. Operação só ocorrerá somente após confirmação das todas etapas realizadas (tudo ou nada). Exemplo, executar operação somente após réplicas factor for maior que 3, e réplicas sincronizadas for maior que 2.
- Padrão: "pelo menos 1 vez", onde que, em caso de falha ou não confirmação, productor reenvia message. Se broker receber message mais de 1 vez, entregará a mesma todas as respectivas vezes;
- No máximo 1 vez: Productor não reenviará message em caso de falha ou não confirmação. Haverá no máximo 1 message e, em caso de falha, consumer não a receberá;
- Exatamente 1 vez: Se houver falha ou não confirmação, productor reenviará menssage. Se broker receber message mais de 1 vez, só persistirá e entregará 1 única vez.
Produção e consumo de messages:
Via console, API Kafka e Kafka Connect. Via console, segue exemplo prático, de comandos, no final do artigo. Via API, tem-se Producer API (permite que producer envie messages), Consumer API (permite que consumer consuma messages, via 1 ou mais topics), Streams API (permite que aplicação atue como processador de fluxo, consumindo messages e gerando resultados processados para outro topic), Connector API (permite criar producer e consumers reutilizáveis, que conectam os topics em sistemas existentes - ex: connector para BD relacional que captura todas alterações em uma table) e Admin API (gerencia e inspeciona topics, brokers e demais objetos do kafka). Kafka Connect: Conectores prontos (declarativo), que só precisam ser instalados e configurados. Pode ser usado com producer (Kafka Connect Source) ou consumer (Kafka Connect Sink). Escalado automaticamente e com balanceamento de carga. Tolerante a falhas. Suporta modo standalone e distributed. Connect em cluster: Connect worker (conexões individuais no cluster, para source e sink). Para escalar, adiciona-se mais workers. Pode-se ter source e sink no mesmo connect. Transformações SMTs (simple messages transform): InsertField, ReplaceField, MaskField, ValueToKey, HostField, ExtractField, SetSchemaMetadata, TimestampRouter, RegexRouter, Filter.
Utilização do Kafka:
- Exemplo prático via console;
- Arquivos em 'kafka/bin': '.sh' são scripts Linux, arquivos '.bat' são scripts Windows;
- Arquivos em 'kafka/lib': bibliotecas Java para conexões via Kafka Connect.
- Passo a passo de uso, via Linux:
- Baixar Kafka e extraí-lo
- (shell 1) Executar ZooKeeper: cd kafka/bin/ && ./zookeeper-server-start.sh ../config/zookeeper.properties
- (shell 2) Executar Kafka: cd kafka/bin && ./kafka-server-start.sh ../config/server.properties
Exemplo prático para criar topics, escrever (simular producer) e consumir (simular consumer) messages nos topics (comandos em '/bin/kafka'):
- Criar topic:
- (shell 3) Executar script de criação de topics: ./kafka-topics.sh --create topic meuTopico --botstrap-server localhost:9092
- Bootstrap server é o endereço do broker: maquina:porta
- Enviar messages:
- (shell 3) ./kafka-console-producer.sh --topic meuTopico --bootstrap-server localhost:9092
- > informar mensagens no console
- Ler messages:
- (shell 4) ./kafka-console-consumer.sh --topic meuTopico --from-beginning --bootstrap-server localhost:9092
- 'from beginning' lerá messages desde antes do shell 4 iniciado (se removê-lo, lerá somente messages após shell 4 iniciado)
- Conforme producer escrever novas messages, consumer irá lendo-as
- ctrl+c para encerrar shell
Listar topics de um broker (via ZooKeeper): ./kafka-topics.sh --zookeeper localhost:2181 --list
Ver informações de topic: ./kafka-topics.sh --describe --topic meuTopico --bootstrap-server localhost:9092
Elaborado por Mateus Schwede
ubsocial.github.io