Rotinas
Fazer o reconhecimento das informações previstas no site. Pesquisar por robots.txt. Procurar mais páginas do site através de Google Hack. Verificar código fonte da página, para localizar pastas de mídias, links (Ex: assets/img.png removemos o 'img.png' e encontramos a pasta com todas as imagens e arquivos internos nela, demais diretórios do sistema, assim como o servidor e SO em que está rodando o site). Para sites gigantes, utiliza-se ferramentas de Web Crawler, que analisam, automaticamente, todo o código fonte, em busca de links para acessos em diretórios e afins.
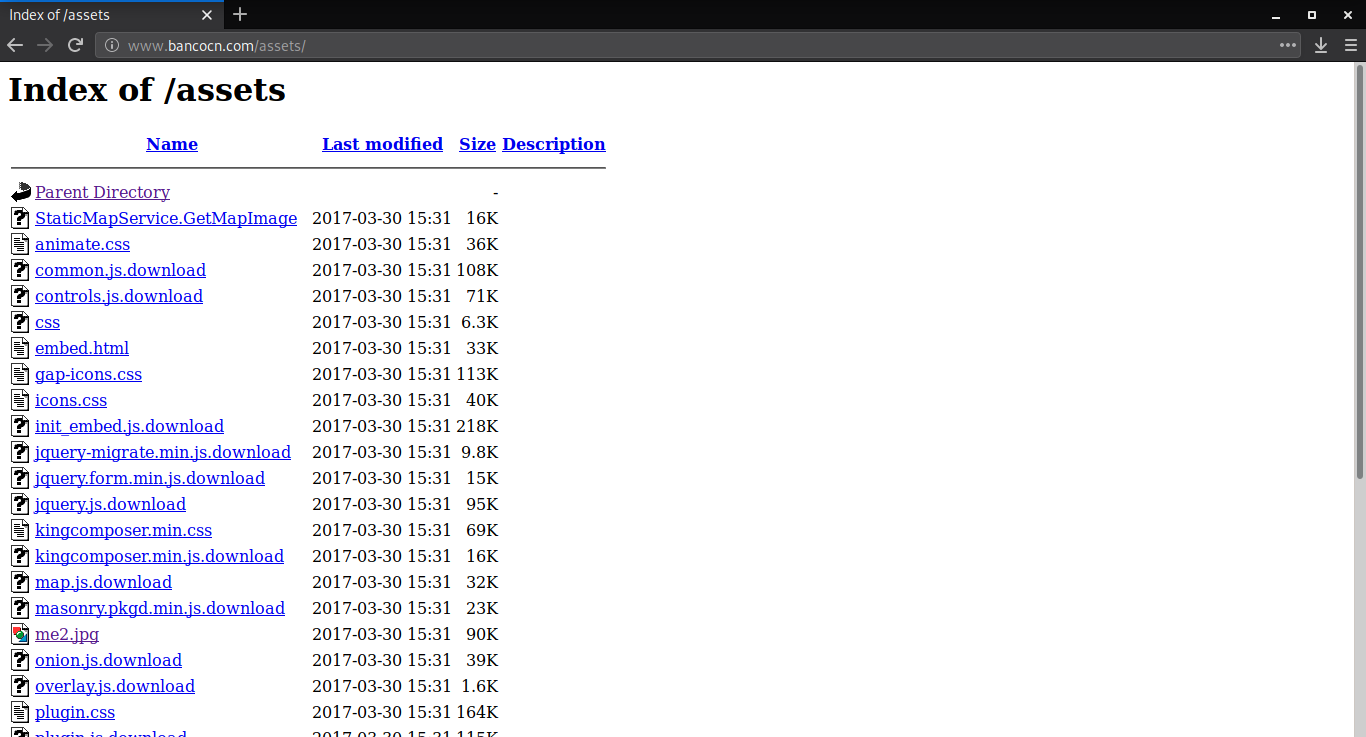
Encontrar diretórios internos com Google Hack
Informe o código abaixo na barra de pesquisas do Google.
intitle:"Index of" site:bancocn.com
Erros padrões
- 404: Página não encontrada;
- 500: Erro interno / Acesso barrado;
- 200: Não há erros (Permissão concedida);
- 304: Já há versão do arquivo salvo no cache do browser, que ainda não fora modificado.
Protocolo HTTP
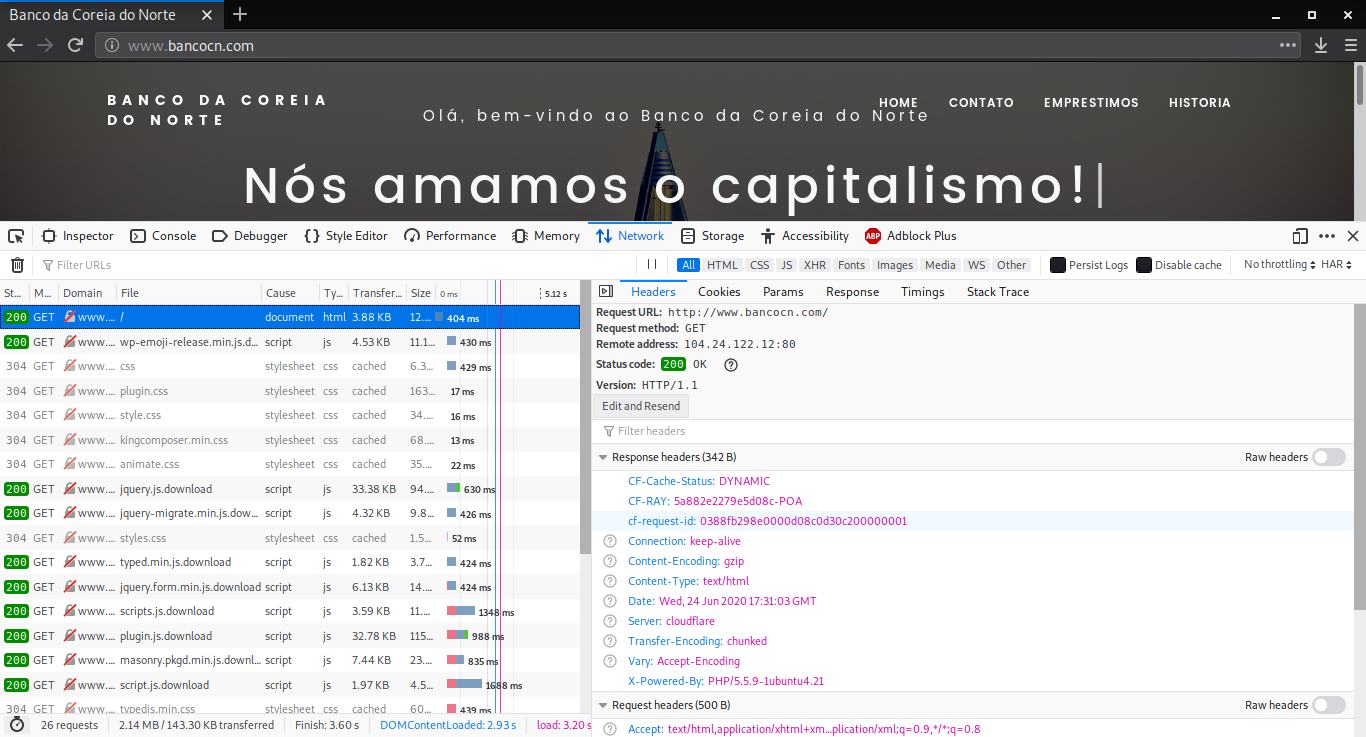
Com F12, conseguimos visualizar a Network, onde serão mostrados todos os passos de requisições realizadas. Com isso, conseguimos localizar o header HTTP do site, responsável pela comunicação com o servidor que envia o resultado solicitado ao browser. Nele, temos 2 cabeçalhos, juntamente com seus parâmetros:
- Request: Para envio
- Host: Url ou ip
- User-Agent: Tipo de navegador e SO do pertencente
- Referer: Página anterior à qual você veio
- Cookie: Compactadores de informações de sessões, autenticação, cookies do firewall(cf: Cloudflare) salvos na máquina (pode-se realizar Bypass com os cookies salvos já autenticados)
- Response: De resposta
- CF-RAY: Parâmetros do firewall Cloudflare
- Server: Identificação do servidor (Real ou Firewall)
- X-Powered-By: Mensagem do servidor identificando linguagem do site (Nem sempre é 100% confirmado)
Para maiores detalhes sobre, pode-se usar o Netcat com os comandos abaixo, que o servidor enviará um Response Header de funcionamento:
nc www.bancocn.com 80
GET / HTTP/1.0
Host: www.bancocn.com
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: pt-BR
Connection: keep-alive
Cookie: __cfduid=dd1f94e17e11b750771b23f1c4d46c96a1592855093; cf_clearance=9d635dc0e4582faca692baac2be1161c33e6e787-1592998676-0-f107732-150; cf_chl_1=3c8d95637607170
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
Os dados acima foram copiados do Network do Browser, do Request Header. O Firewall, não aceitará request via terminal, pois solicita validação via JavaScript, que está presente somente no navegador, sendo ausente no terminal, do qual está sendo enviada a requisição. Há softwares, desenvolvidos com Python, para burlar tal problema. A solução para tal problema é enviar o Request Header, gerado numa requisição via Browser, por inteiro (remover somente o 'Acept-Ecoding'), incluindo os cookies já validados pelo firewall, conforme no exemplo acima. É provável que o Response Header será de 200, ou seja, conexão bem sucedida.
Brute Force de diretórios
Pode-se fazer manualmente, inserindo na url (Ex: bancocn.com/admin, bancocn.com/medias, bancocn.com/webmail...), ou de forma automatizada com o Dirb.
Dirb
dirb url listaDiretorios.txt (a lista é opcional, pois há uma default caso ñ informada)
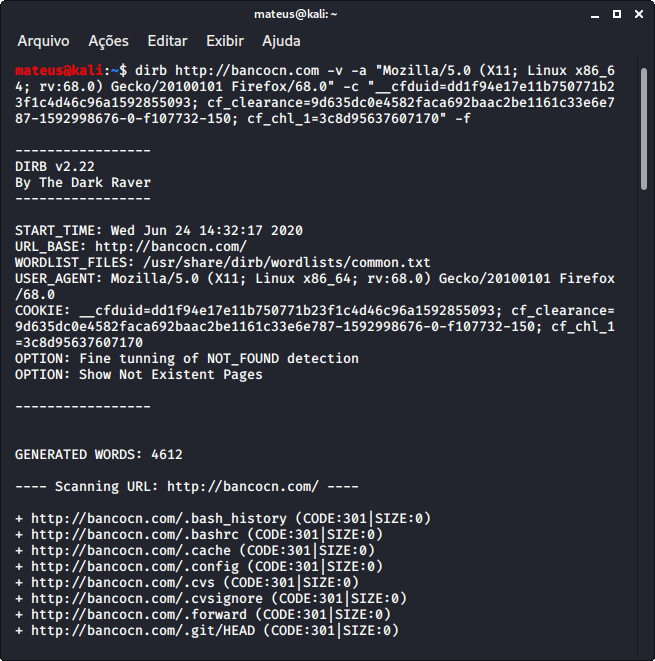
dirb http://bancocn.com -v (-v mostra procedimento)
Nos casos com Firewall, é muito provável que o dirb não funcione, informando erro 503 ou afins. Dessa forma, terá de ser feito Bypass, utilizando os dados do Request header. O -a representa o User-agent, copiado do Request header validado pelo Cloudflare. O -c representão os cookies do Request header. O -f representa uma pesquisa refinada. Esse Bypass funcionará por tempo limitado, pois o firewall solicitará novos dados do Header, que deverá ser alterado no comando abaixo (-a e -c). Para uma pesquisa mais limpa, remova o -v, que o dirb mostrará apenas os resultados satisfatórios. Pode-se inclusive executar dirb dentro de pastas descobertas pelo próprio dirb.
dirb http://bancocn.com -v -a "Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0" -c "__cfduid=dd1f94e17e11b750771b23f1c4d46c96a1592855093; cf_clearance=9d635dc0e4582faca692baac2be1161c33e6e787-1592998676-0-f107732-150; cf_chl_1=3c8d95637607170" -f
SQL Injection
Enviar dados diferenciais na url, a fim de obter informações sobre o banco de dados.
http://www.bancocn.com/cat.php?id=1
http://www.bancocn.com/cat.php?id=' (Troca-se o 1 por aspa simples)
Elaborado por Mateus Schwede
ubsocial.github.io